Google AI Overviews does not use top-ranking organic results. Our analysis reveals a completely separate retrieval system that extracts individual passages, scores them for relevance & decides whether to cite them.
Ex-Stanford AI Researcher specialising in search algorithms and LLM optimisation.
June 2, 2026
Published: January 23, 2026|Updated: June 2, 2026
9 mins
TL;DR
Google AI Overviews loads content asynchronously through a dedicated /async/folsrch endpoint, separate from regular search results
The system uses ML routing tokens (mlro) and protobuf-encoded model configs (mrc) to select which AI model handles each query
Citations are pulled from retrieved source documents during a server-side retrieval phase that takes approximately 200ms
The entire AI generation process takes 1.4 to 5 seconds, with the AI inference phase consuming around 1.2 seconds
Server-side decision logic determines whether to show an AI Overview or display "not available" based on query type, intent, and experiment flags
Google AI Overviews does not pull citations from your top-ranking organic results. Our network traffic analysis reveals a completely separate retrieval system that extracts individual passages, scores them for relevance, and decides whether to cite them in under 200 milliseconds. This means a page ranking #15 organically can earn a citation while a #1 result gets ignored.
Understanding these internal mechanics gives you a real advantage over competitors still optimizing for traditional rankings. This article breaks down exactly how the system retrieves information, selects sources, and generates citations based on our analysis of actual network traffic. If you want the foundational context on how LLM retrieval systems work, start there first.
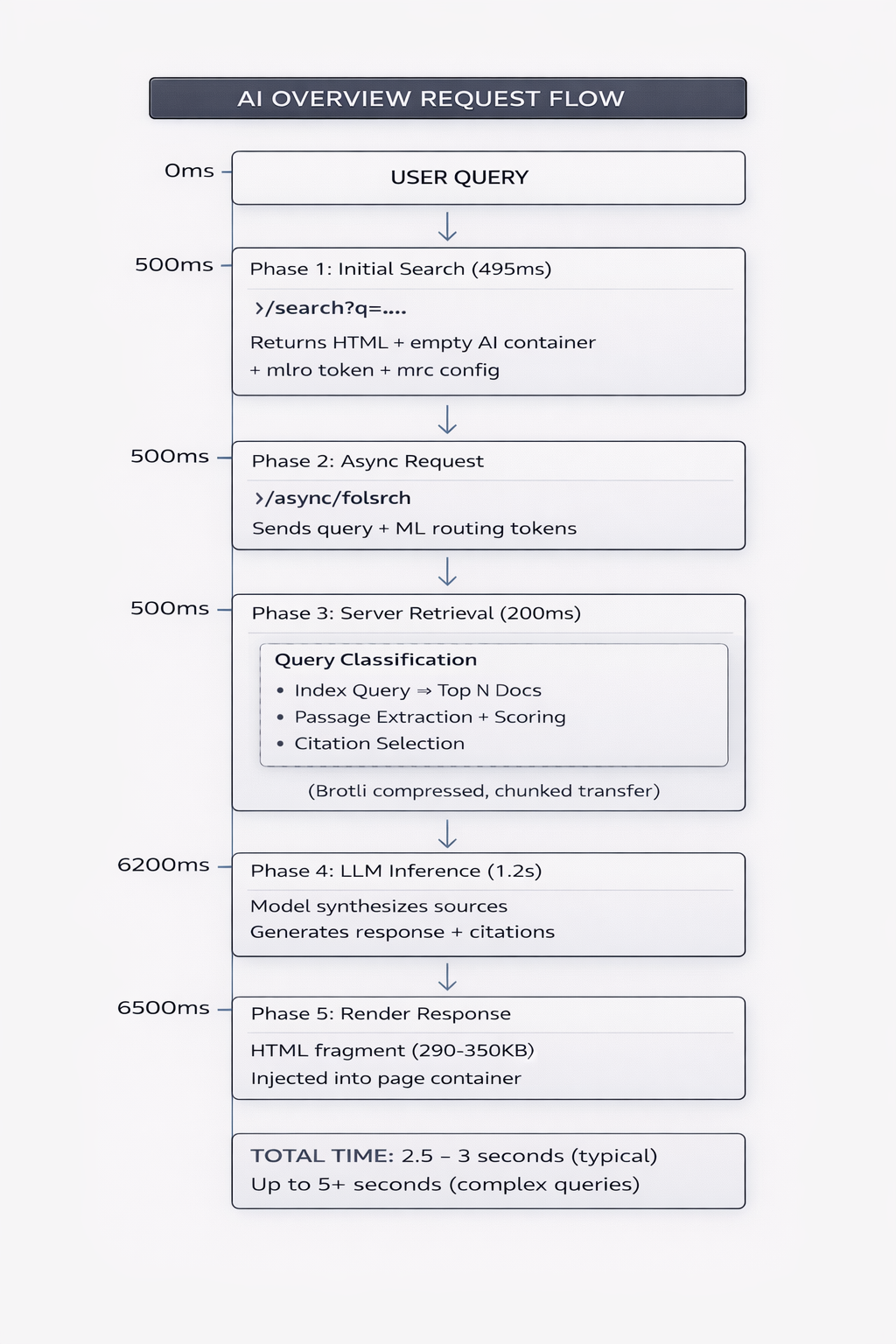
What happens when you search: the complete request flow
When a user enters a query, Google AI Overviews follows a five-phase process that happens in roughly 2.5 to 3 seconds. Understanding this flow helps you see exactly where your content needs to be positioned to earn a citation.
Phase 1: Initial search and container setup
The first request goes to /search?q=... and returns the main HTML page. This response includes an empty AI Overview container with the loading state "Searching..." visible to users. The container includes critical data attributes that tell the system what to load next.
Key data attributes embedded in the initial response:
data-aim="1" indicates AI Overview mode is enabled for this query
data-mlro contains a 100+ character ML routing token
data-mrc holds a protobuf-encoded model configuration (typically CAA4gANQAWgA)
data-async-type="folsrch" specifies the async loading mechanism
This initial phase completes in approximately 495ms with a response size of around 500KB.
Phase 2: Async content request
After the initial page renders, a second request fires to /async/folsrch with parameters including the query, ML routing tokens, and target container ID. This is where the AI system actually does its work.
The folsrch endpoint receives these key parameters:
q - the search query
mlro - the ML routing token (100+ characters of base64-encoded context)
mlros - a signature validating the mlro token
mrc - protobuf model routing config
_id=B2Jtyd - the target container for content injection
Phase 3: Server-side retrieval and decision
Here is where citations actually get selected. The server runs query classification to determine the query type (comparison, how-to, factual, or complex) and the appropriate domain. Based on this analysis, it queries the Google Search index to retrieve the top N relevant documents.
During this retrieval phase, the system:
Extracts relevant passages from indexed documents
Scores each passage for query relevance
Selects sources that will be used for citation
Determines whether an AI Overview should be shown at all
This phase takes approximately 200ms and is where your content either makes the cut or gets excluded.
Phase 4: AI inference and generation
With sources retrieved, the LLM processes the query and source passages together. The model synthesizes information from multiple sources, structures the response appropriately for the query type, generates attribution links to specific sources, and applies safety filters.
Our traffic analysis shows this inference phase takes approximately 1,200ms for standard queries, though complex queries can extend to 5+ seconds. The model receives the user query, retrieved source passages, query context, and output format constraints as inputs.
Phase 5: Response delivery
The generated content streams back as an HTML fragment ranging from 290KB to 350KB. This fragment gets injected into the pre-rendered container on the page. The response includes the AI-generated summary text, citation links with source attribution, and structured comparison data when relevant.
How citations are selected: the retrieval mechanism
The citation selection process happens during Phase 3, and understanding it is critical for AEO strategy. Google does not simply pull from the top organic results. Instead, it runs a passage retrieval system optimized for answering the specific query. This retrieval-augmented generation (RAG) approach mirrors what other AI systems use, as documented in Google's research on retrieval-augmented language models.
Rather than citing entire pages, the system extracts specific passages that directly answer elements of the query. This means a single piece of content can be cited multiple times across different AI Overviews if it contains multiple relevant passages. The implication for content creators is clear. Structuring content with distinct, self-contained answer blocks increases your citation surface area. Our step-by-step guide to getting cited by AI covers the practical implementation of this approach.
Source scoring
Retrieved passages are scored for query relevance before being passed to the LLM. While we cannot observe the exact scoring algorithm from traffic analysis, the sources that appear in captured responses consistently come from high-authority domains with content that directly addresses the query in clear, factual language.
In one captured example comparing OLED and QLED TVs, citations included rtings.com, cnet.com, techradar.com, tomsguide.com, and digitaltrends.com. All of these sources had dedicated comparison content with structured formats. This aligns with Google's published guidance on creating helpful content that demonstrates first-hand expertise.
Citation format in responses
Citations appear in the response HTML with tracking parameters. Each citation includes a data-ved attribute for click attribution and analytics. The citation links are grouped in a sources div and rendered below the AI-generated content.
The ML routing system: how Google selects models
One of the most interesting findings from our traffic analysis is the ML routing system that determines which model handles each query. This happens through two key parameters.
The mlro token
The mlro parameter is a 100+ character base64-encoded token that contains:
Model selection preferences
User and session context
Experiment group assignment
Query classification results
Each request gets a unique mlro token, meaning model selection happens dynamically per query rather than being fixed.
When AI Overviews do not appear: exclusion factors
Not every query triggers an AI Overview. Our analysis captured several queries that returned "An AI Overview is not available for this search" messages, revealing likely exclusion factors.
Commercial and purchase intent
Queries with explicit buying signals may be excluded. The query "should I buy airpods pro from amazon or apple store directly" did not receive an AI Overview, likely because the commercial intent triggers different handling.
Meta queries about Google
Questions about Google's own services and features appear to be excluded. The query "ai overviews google" returned no AI Overview.
Regional availability
The captured traffic used the en-PT locale, and some queries that would typically trigger AI Overviews in the US did not show content. Regional rollout remains uneven.
A/B experiment groups
The __Secure-BUCKET cookie assigns users to experiment groups. Users in control groups may see fewer or no AI Overviews regardless of query type. Our analysis identified 98 active experiment IDs running simultaneously.
Performance metrics: what Google measures
Google tracks AI Overview performance extensively through dedicated timing metrics sent via /gen_204 telemetry beacons. Understanding these metrics reveals what Google optimizes for.
SIRT metrics (Server Initial Response Time)
sirt-aimc - AI Model Content response time
sirt-aimfl - AI Model Full Load time
sirt-mfl - Model Full Load time
sirt-dfa - Direct First Answer time
AI timing flags
afts - AI First Time Start (loading began, typically 29-46ms)
aftr - AI First Time Render (finished rendering, typically 61ms)
afti - AI First Time Interactive (became interactive, 73-189ms)
These metrics suggest Google prioritizes fast initial response times while allowing longer generation for complex queries.
What this means for AI visibility strategy
Understanding Google AI Overviews' internal mechanisms, which an AI overview tracker can help monitor, points to several actionable strategies for improving citation rate.
Structure content for passage retrieval
Since the system extracts passages rather than evaluating whole pages, structure your content with distinct, self-contained sections of 200 to 400 words each. Each section should directly answer a specific question without requiring context from other sections.
Target the retrieval phase
Your content needs to rank well in the passage retrieval step, not just in traditional organic rankings. This means including the exact language users search with, answering questions directly in the first sentences of sections, and using structured data to help the system understand your content.
Build third-party validation
The sources appearing in AI Overview citations share common characteristics. They tend to be recognized authority sites in their domains with extensive external validation through mentions and links. This is why entity SEO and brand recognition by LLMs has become critical for AI visibility.
Match query intent with content format
Different query types route to different models and expect different response formats. Comparison queries need structured pros and cons. How-to queries need step-by-step sequences. Factual queries need direct answers with supporting evidence. For a comprehensive checklist of optimization tactics, see our guide to 15 AEO best practices for winning AI citations.
What this means for marketing leaders
The technical findings above translate into specific actions your team can prioritize today.
Reframe how you think about rankings. Organic position does not determine citation. The retrieval system scores individual passages, which means a page ranking #15 can outperform a #1 result. Audit your content for passage quality, not just keyword rankings.
Create self-contained answer blocks of 200 to 400 words. The system extracts passages independently, so each section needs to stand alone. Remove dependencies on surrounding context and ensure every block directly answers a specific question.
Match your content format to query type. Different queries route to different models expecting different structures. Comparison queries need pros and cons tables. How-to queries need numbered steps. Factual queries need direct answers with supporting evidence in the first sentence.
Prioritize speed-to-publish over perfection. The entire citation decision happens in roughly 200 milliseconds during the retrieval phase. Google is optimizing for fast, accurate passage extraction. Content that clearly answers questions with specific language will outperform polished but vague pieces.
Build third-party validation as a citation multiplier. The sources appearing in captured AI Overviews consistently came from high-authority domains with extensive external validation. Your on-site content works harder when supported by mentions across Reddit, industry publications, and review sites.
Treat structured data as required infrastructure. FAQ schema, how-to markup, and entity definitions help the retrieval system understand and extract your content. This is not optional optimization. It directly affects whether your passages score high enough to clear the citation threshold.
How Discovered Labs helps with AI visibility
Discovered Labs specializes in helping B2B SaaS teams improve their AI visibility and citation rate across answer engines. Our approach uses tools that track how you appear in AI answers, combined with a content methodology (our CITABLE framework) designed specifically for passage retrieval systems.
We help clients identify their current share of voice in relevant AI answers, create content optimized for passage-level citation, and build the third-party mentions that establish authority with AI systems.
FAQs
How long does it take for Google to generate an AI Overview?
Based on our traffic analysis, the complete process takes 2.5 to 3 seconds for typical queries. The AI inference phase alone takes approximately 1.2 seconds, with retrieval adding another 200ms and delivery taking 100ms. Complex queries can extend to 5+ seconds.
Does ranking in the top 10 organic results guarantee a citation?
No. AI Overview citations come from passage retrieval, which operates independently from organic rankings. A page that ranks well organically may not be cited if its content is not structured for passage extraction. Conversely, content from lower-ranking pages can earn citations if it directly answers elements of the query.
Can I track whether my content appears in AI Overviews?
Traditional rank tracking tools do not capture AI Overview citations effectively because the content loads asynchronously and varies by user experiment group. You need specialized share of voice tools that monitor AI answers across representative query sets.
Why does my content appear in AI Overviews for some queries but not others?
Several factors influence citation selection. Query type affects which model handles the request. Your content structure determines whether relevant passages can be extracted. Experiment flags may show different results to different users. And some query categories (commercial intent, meta queries) may be excluded entirely.
Does structured data help with AI Overview citations?
Structured data helps the retrieval system understand your content and extract relevant passages. FAQ schema, how-to schema, and clear entity markup all provide signals that can improve your content's retrieval score during the passage selection phase. Google's structured data documentation provides the technical specifications for implementation.
Our team analyzed network traffic from Google AI Mode in January 2026. The capture included 547 Google flows and over 1,300 total requests during AI Mode sessions. The findings paint a clear picture of how Google is preparing to monetize AI-generated search results.
Google AI Mode is not simply a UI layer on top of traditional search. It is a completely different rendering pipeline. Google AI Mode runs 816 active experiments simultaneously, routes queries through five distinct backend services, and takes 6.5 seconds on average to generate a response.
We breakdown how how AI Overviews work and currently contain zero embedded ads, and traditional SERP ad slots remain intact above and below. But the technical groundwork for future monetization is already visible in the code.
We analyzed 1k+ traffic flows from Gemini's web interface. Understanding these mechanisms helps you optimize your content for AI visibility because Gemini treats structured data, entity relationships, and third-party validation as core signals when deciding what to cite.