Executive summary
TL;DR
Prompt-content alignment is the single highest-ROI lever in AI SEO. Pages whose language mirrors how buyers prompt AI engines show a standardised effect roughly three times larger than the next-strongest signal. The standard AEO checklist (FAQ, TLDR, schema, page speed, author bios) produces real, measurable gains (they are not optional) but they work best as a layer on top of strong content alignment, not a substitute for it. AI-perceived domain authority dominates everything: in our SHAP analysis, a domain's AI-perceived domain authority was 6 times more influential than the strongest individual page-level feature. AI engines disagree about freshness: Claude favours recent content while ChatGPT and Gemini cite older content. And page format matters: pricing and comparison pages punch above their weight on AI citations across the entire funnel.
Most published AEO best practices are pattern-matched from Google SEO playbooks or anecdotal observations from individual ChatGPT outputs. Few are backed by large-N, multivariate analysis. To our knowledge this is one of the largest studies of AI citation predictors published to date, and one of the longest time horizons: six months of continuous benchmarking across four engines.
We analysed 2 million AI citation observations across six months from the four major B2B-relevant AI engines (ChatGPT, Claude, Google AI, Gemini), and crawled, parsed, and feature-engineered 10,000 of the cited pages at the content and page speed performance level. The two datasets were joined into a single wide table, and every plausible predictor of citation count was tested against a rigorous statistical framework.
Five findings that survived every robustness check
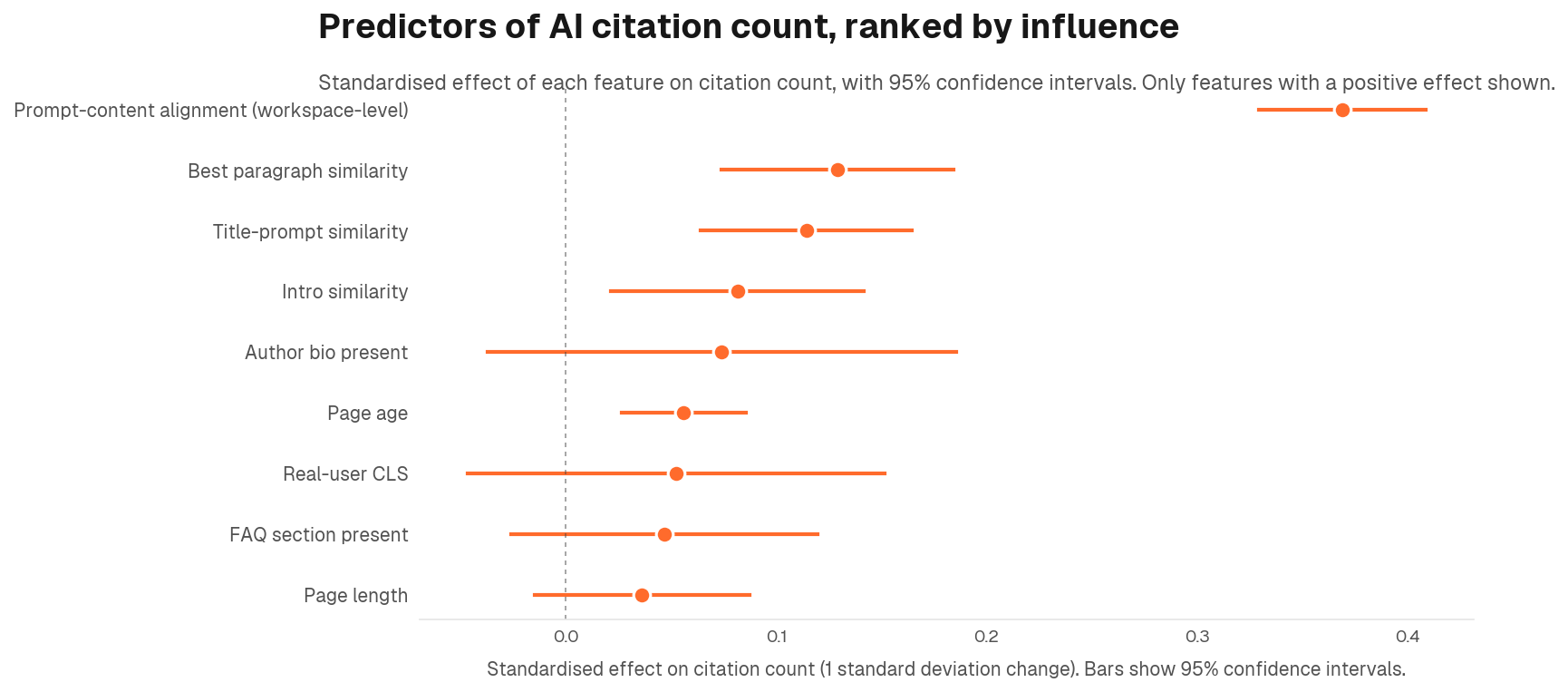
- Prompt-content alignment is the dominant lever. Pages whose language and concepts mirror buyer prompts show a standardised effect roughly 3x larger than the next-strongest page-level signal. Standardised effect size: +0.37.
- The standard AEO checklist produces measurable gains. FAQ blocks, TLDR/BLUF sections, schema markup, page speed, and author bios all show positive effects on citation count. They compound strongest when alignment is already in place.
- AI engines disagree about content freshness. Claude favours recent content (median citation age 5 months). ChatGPT and Gemini cite older content more readily (median 8 months and beyond). Calibrate to the most demanding engine: a cadence that satisfies Claude keeps you competitive across all of them.
- Page format matters independently of content quality. Pricing pages and comparison content earn disproportionately more AI citations than blog content, even after controlling for length, alignment, and AI-perceived domain authority.
- AI-perceived domain authority dominates everything. A domain's AI-perceived domain authority was 6 times more influential than the strongest individual page-level feature. For challenger brands, off-page authority is upstream of every on-page lever in this study.
The aim of this report is not to prescribe tactics. It is to give marketers a defensible map of which levers are real, which are real but small, and which are noise.
Methodology
The headline numbers behind the analysis:
- Capture window: six months across our AEO benchmarking infrastructure
- Citation observations: approximately 2 million prompt, engine, and citation tuples
- Pages crawled and parsed: 10,000 distinct cited URLs across four classification buckets (own brand, competitor brand, true third-party, hybrid)
- PageSpeed data: 4,815 own and competitor pages with both mobile and desktop runs, 95.6% URL-level coverage in the Chrome User Experience Report
- Features computed: 60+ structural, alignment, recency, and infrastructure attributes per page
How do we know if an effect is real or not?
The core challenge in this kind of study is separating genuine causal signals from noise, confounding, and statistical artefacts. We apply nine separate robustness checks to every predictor. A feature only enters the findings if it survives at least four of them independently.
- Multilevel regression with domain fixed effects to absorb brand-level variance
- False Discovery Rate correction (Benjamini-Hochberg) across all hypothesis tests
- Stability-selection Lasso across 200 bootstrap samples to identify features that survive proper feature selection
- Double Machine Learning to estimate orthogonalised partial effects
- Factor analysis on collinear predictor groups to test whether speed metrics measure one thing or several
- Generalized Additive Models to test for non-linear relationships
- Sensitivity analysis across five alternative subset definitions
- Leave-one-domain-out replication across the top eight domains in the sample
- Temporal hold-out validation: model trained on citations up to March 2026, tested on April 2026 citations on the same URLs
For more detail on our general approach to AI visibility research, see our AEO methodology.
What actually drives AI citations
The single most predictive feature of AI citation count, after controlling for domain, page type, content depth, and page age, is prompt-content alignment. This measures the degree to which the language and concepts on a page overlap with the full set of prompts used across the page's AEO workspace: all buyer questions, including ones the page was never cited for. For the technical mechanism behind why this matters, see how AI systems decide what to cite.
Standardised regression coefficient: +0.37 (95% confidence interval: +0.33 to +0.41). One standard deviation increase in alignment corresponds to roughly 30% more citations on average. For tactical guidance on operationalising alignment, see our AI citation strategy.
Why alignment leads the field
Alignment is not just the strongest predictor: it is also the most robust. It clears every methodological hurdle we applied, which is unusual for a single feature in a study this size.
- Statistically significant after FDR correction at q < 1e-73
- Selected in 100% of 200 stability-selection Lasso bootstraps
- Survives Double Machine Learning orthogonalisation, with β = +0.35 after gradient-boosted models remove all confounder variance
- Significant in three of the four engines tested, with consistent positive direction across all four
- The Generalized Additive Model smooth shows a monotonic relationship with no sign of saturation. Every incremental gain in alignment continues to compound
Other signals matter too
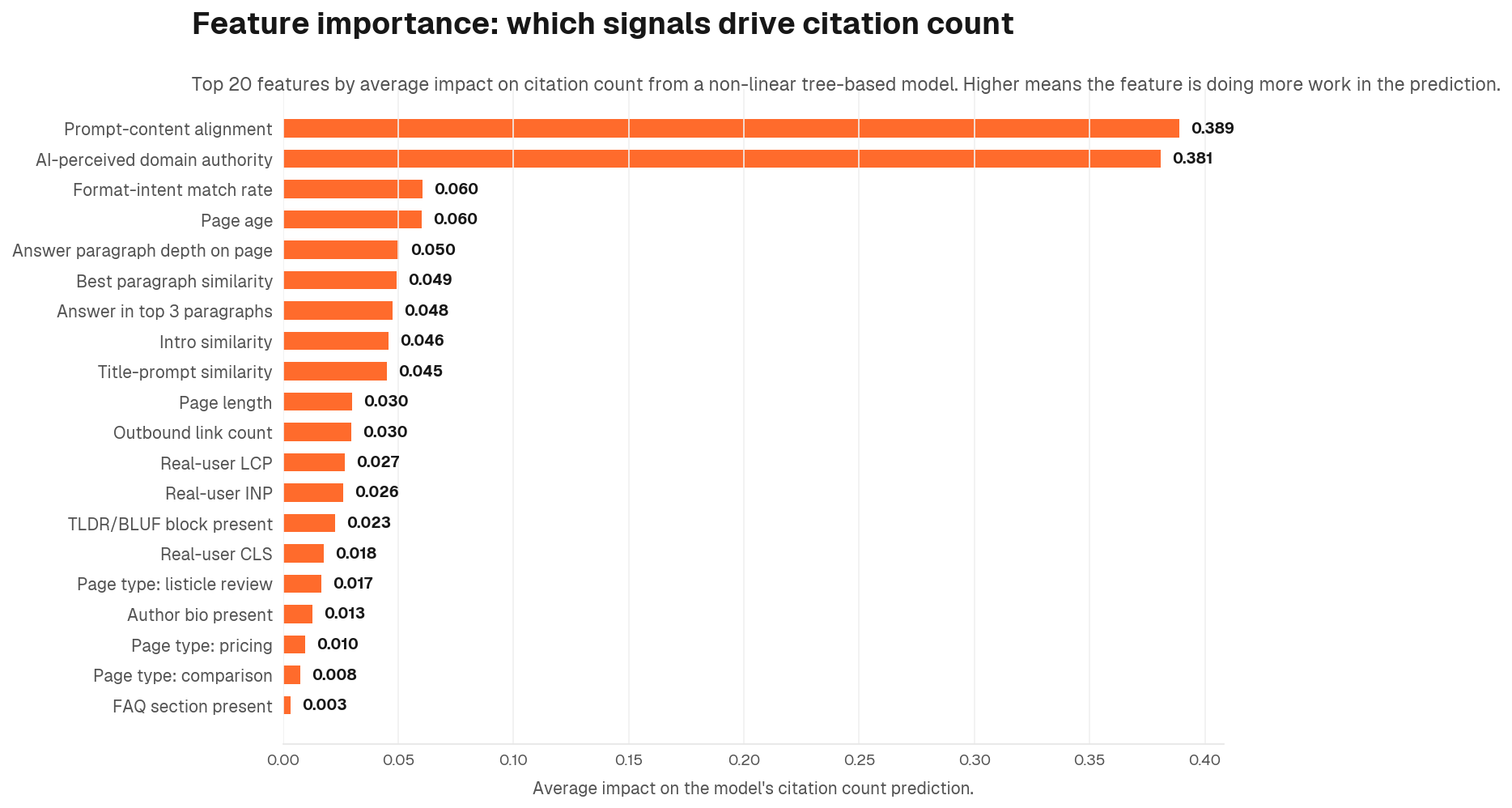
Alignment leads, but the picture is not one-dimensional. Several other features show consistent, meaningful positive effects in their own right. These are not noise and should not be treated as secondary concerns. They are independent contributions that stack on top of alignment.
- Page length (β = +0.13): Longer pages accumulate more citations, holding everything else constant. Depth signals authority and gives AI engines more to draw from
- Title-prompt similarity (β = +0.09): Pages whose titles mirror how buyers phrase their questions earn more citations. The title is the first signal an AI engine reads
- Page age (β = +0.05): Older pages carry a citation history that compounds over time. Newer pages are not penalised, but established pages hold an advantage
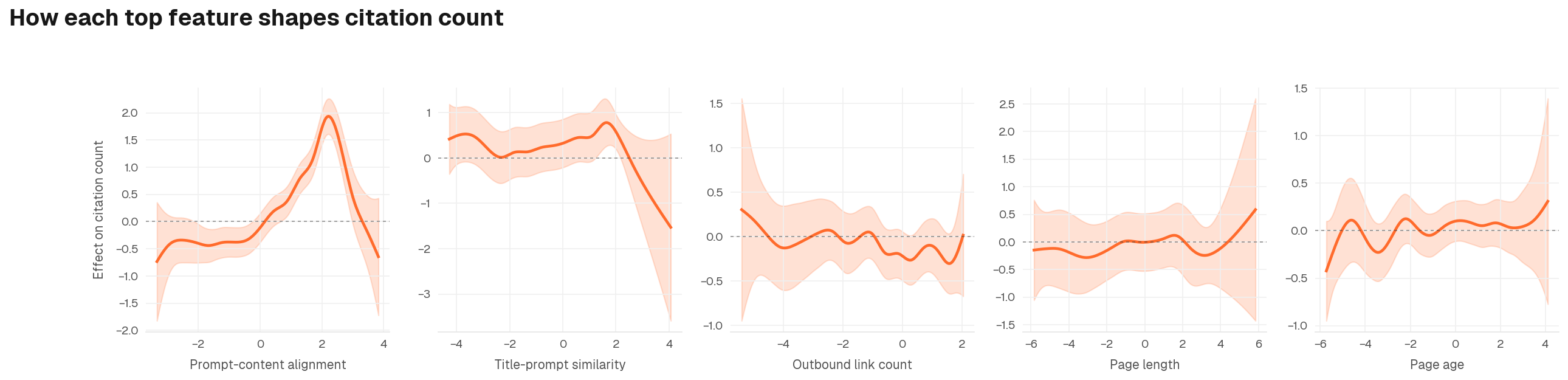
This chart reveals the shape of each effect, not just the average slope.
- Prompt-content alignment: The curve does not flatten at the right edge. There is no ceiling: every increment of alignment continues to compound, and high-alignment pages have no natural cap on citation gains
- Title-prompt similarity: Strong positive lift in the mid-range, but the effect becomes noisier at extremes. Getting the title right matters; over-engineering it yields diminishing returns
- Outbound link count: The relationship is relatively flat, suggesting links alone are not a meaningful citation driver once content quality and alignment are controlled for
- Page length: The lift is broadly positive across the observed range. More depth gives AI engines more to draw from, though variance widens at the high end
- Page age: The effect accumulates gradually across the range, suggesting established pages carry compounding citation history. This sits alongside the engine-level recency findings below, and the two effects likely operate through different mechanisms
Where on the page matters too
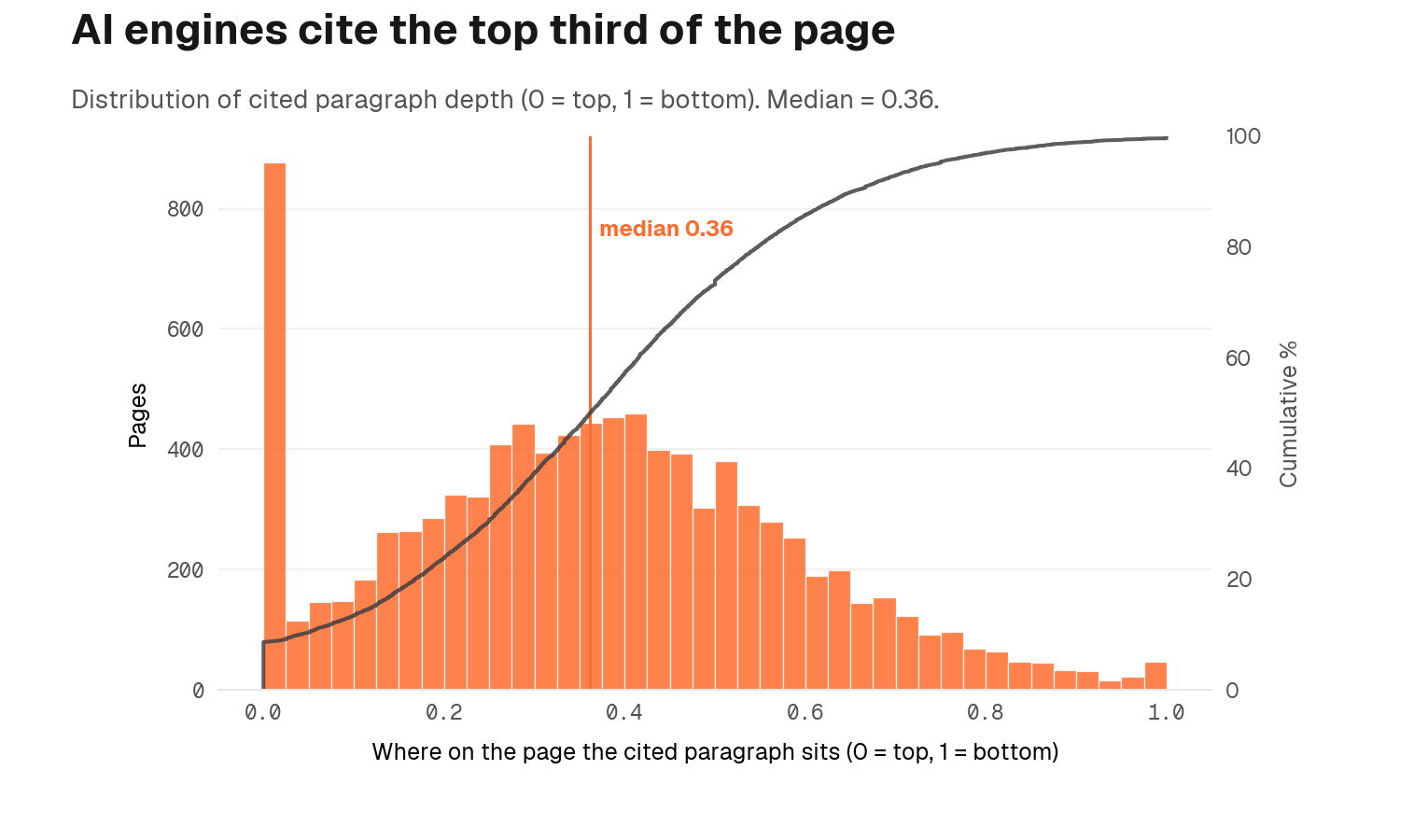
A complementary finding is that the citation isn't just about whether the page is aligned, but where on the page the alignment lives. The paragraph that AI engines cite most often sits at a median depth of 0.36 (where 0 is top of page and 1 is bottom). In other words, AI is reading the top third of the page. If your most aligned content lives below the fold, much of its value is lost.
"Prompt-content alignment is your number one lever. Pages whose words and phrasing match how your buyers actually ask questions show a standardised effect roughly three times larger than the next-strongest page-level signal. The work is not keyword stuffing. It is harvesting buyer language from sales calls, support tickets, Reddit threads, and customer interviews, then writing as they talk."

Ben Moore, Co-founder at Discovered Labs
On-page signals: important, and right behind alignment
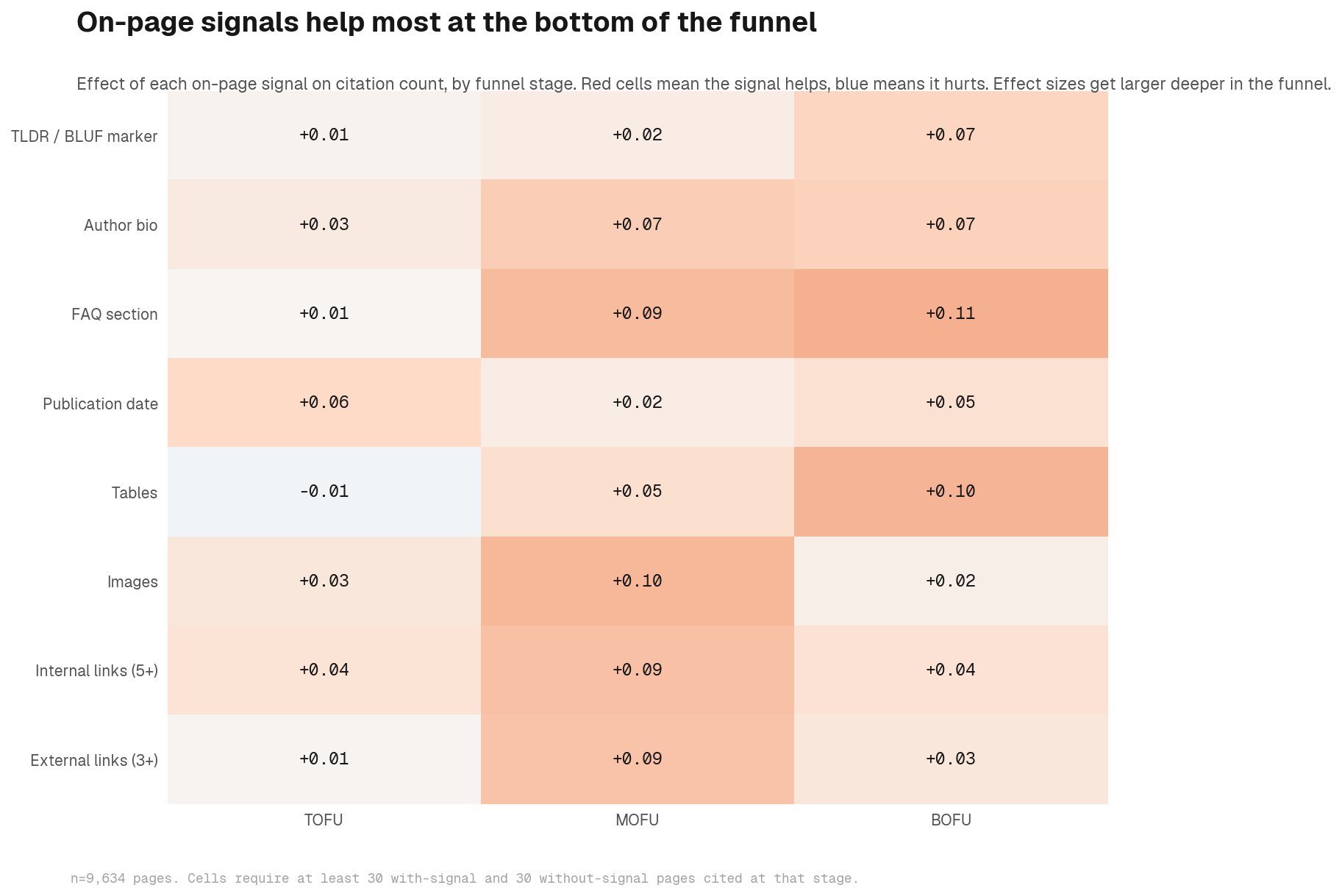
Prompt-content alignment is the dominant lever, but the AEO checklist that follows it is not a rounding error. A standard AEO checklist (see our 15 AEO best practices) covering Core Web Vitals, schema markup, FAQ sections, TLDR/BLUF blocks, author bios, and structured headings shows consistent positive effects across the data. These are the signals that separate well-optimised pages from otherwise-equal competitors once alignment is in place. We tested each as a predictor of citation count, controlling for domain, content depth, page type, and page age.
The findings, expressed as standardised regression coefficients on the log of citation count:
- FAQ section: β = +0.07 on third-party pages. Smaller and conditional on domain in the multivariate model. For implementation, see our FAQ optimisation guide
- TLDR/BLUF block: β = +0.05. Positive but small
- Author bio: β = +0.02. The effect collapses after content-depth controls are applied
- Real-user Core Web Vitals (LCP, INP, CLS): factor analysis collapses these into latent factors that show no significant effect on citations after domain control. For technical context, see page speed and Core Web Vitals for AI crawlability
- Synthetic Lighthouse Performance score: no significant effect after controls
- Schema markup: no significant independent effect detected in this sample; schema likely contributes indirectly through content structure rather than as a standalone citation signal
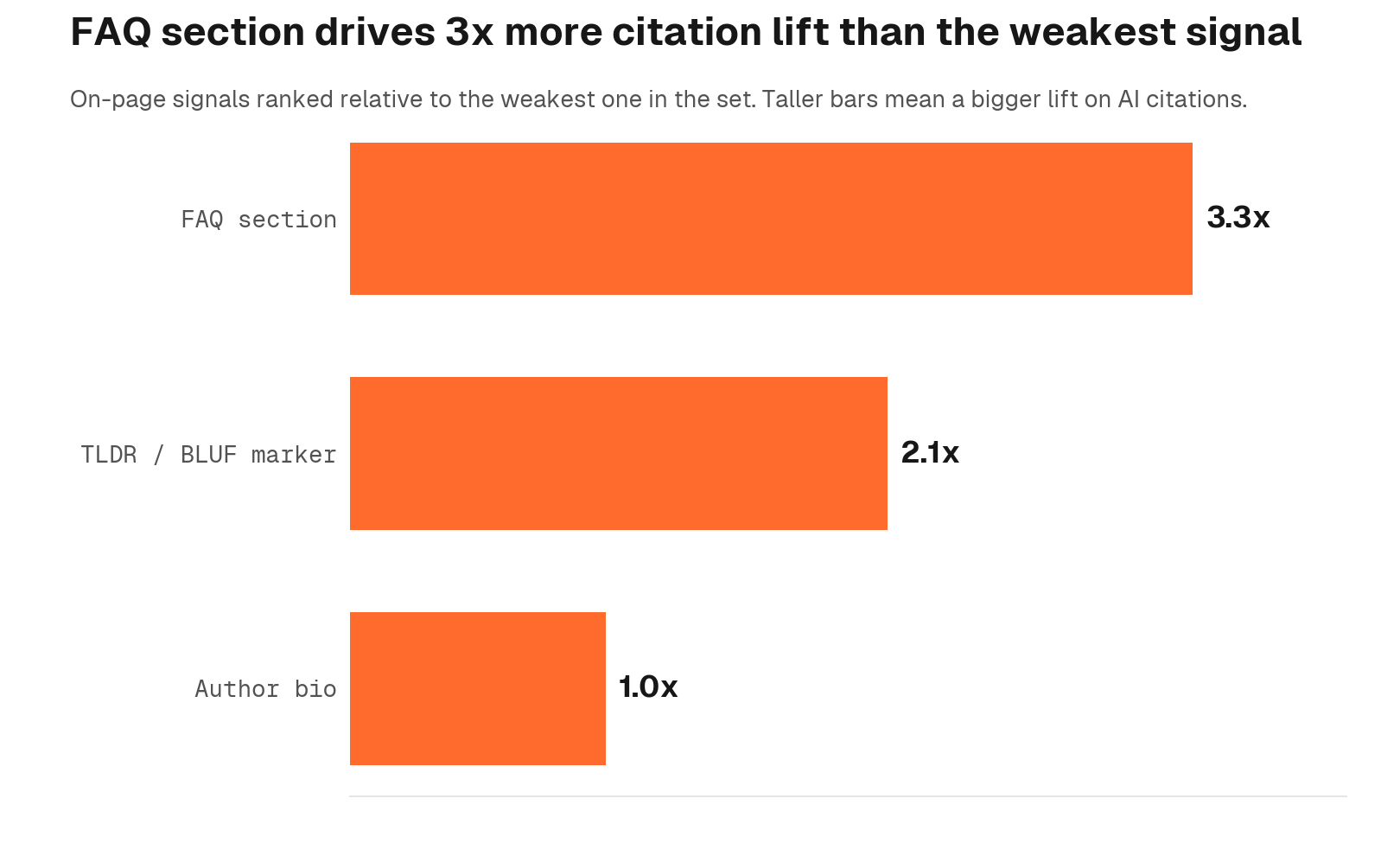
These signals compound meaningfully on a well-aligned content base. A page that speaks the buyer's language and carries FAQ structure, clean schema, a credible author bio, and fast load times will consistently outperform one that has alignment alone. The order matters, but so does completing the stack.
Implications for AEO best practice
FAQ sections, TLDRs, schema markup, page speed, and author bios all produce measurable citation lift. Execute them alongside alignment work, not after it is "finished." The compounding effect is real: each layer reinforces the others, and pages that complete the full stack pull further ahead over time.
If you need help operationalising this, our AEO services sequence the work in the right order, alignment first, structure second.
AI engines have different appetites
Different engines exhibit measurably different content lifecycles and format preferences. "Optimising for AI" is not a single-target problem. For a platform-by-platform companion piece, see how each platform cites sources differently.
Recency preferences across engines
| Engine | Median citation age (months) |
|---|---|
| Claude | 5.1 |
| Google AI | 6.0 |
| Gemini | 7.8 |
| ChatGPT | 8.0 |
Claude shows the steepest decay curve: 60% of its citations are on content under six months old. ChatGPT exhibits the shallowest decay; only 40% of its citations come from content under six months. Engine preferences vary, but since user behaviour across models can shift quickly, optimising to the most demanding threshold keeps you competitive on all fronts. We unpack the cadence implications in why content freshness matters for AI citation.
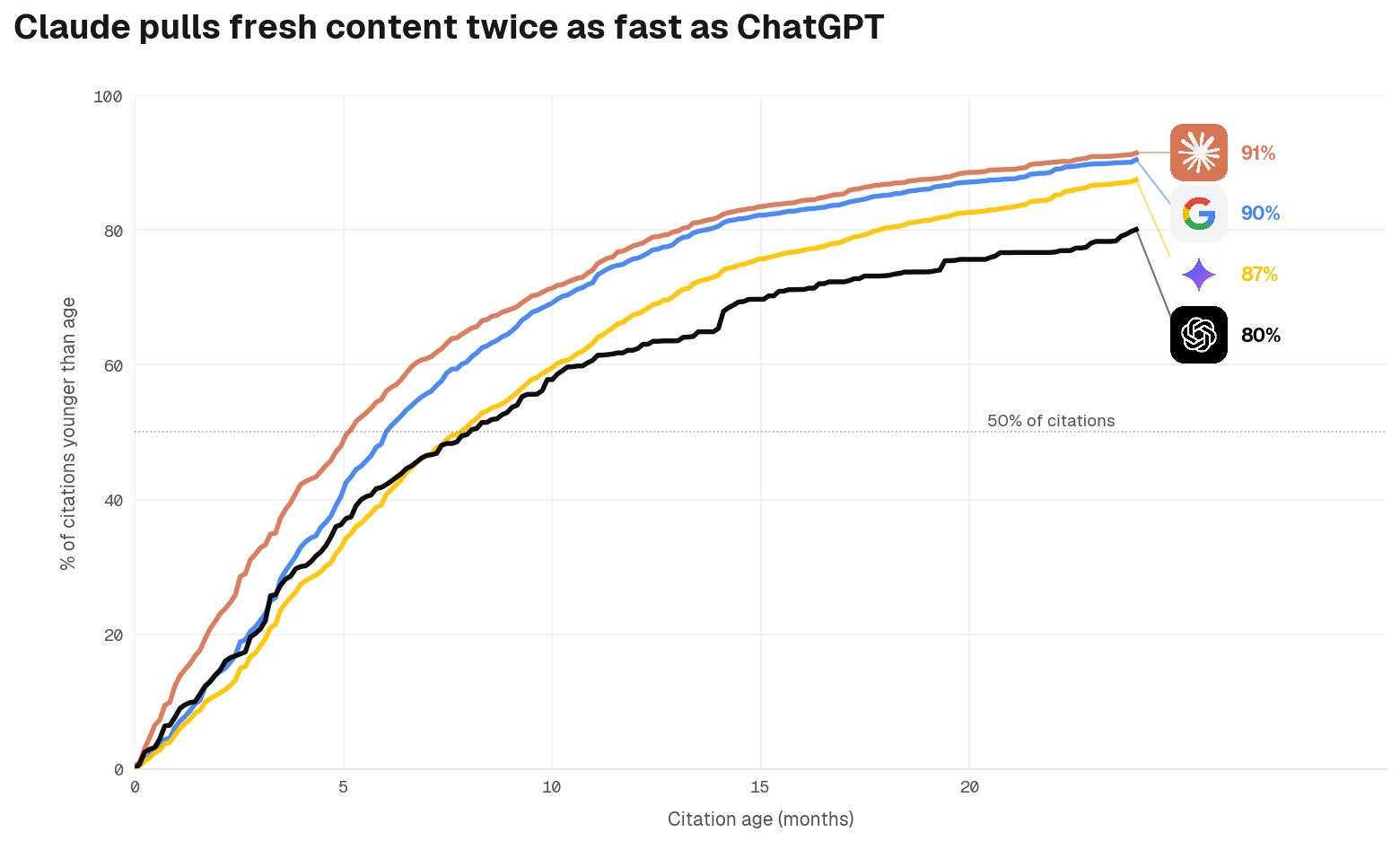
Engines treat the same web differently
Engines also differ in how much they prefer brand-controlled (own or competitor) pages over true third-party content. ChatGPT cites brand pages disproportionately: 39% of its unique cited URLs are brand-controlled, against 14% on Gemini.
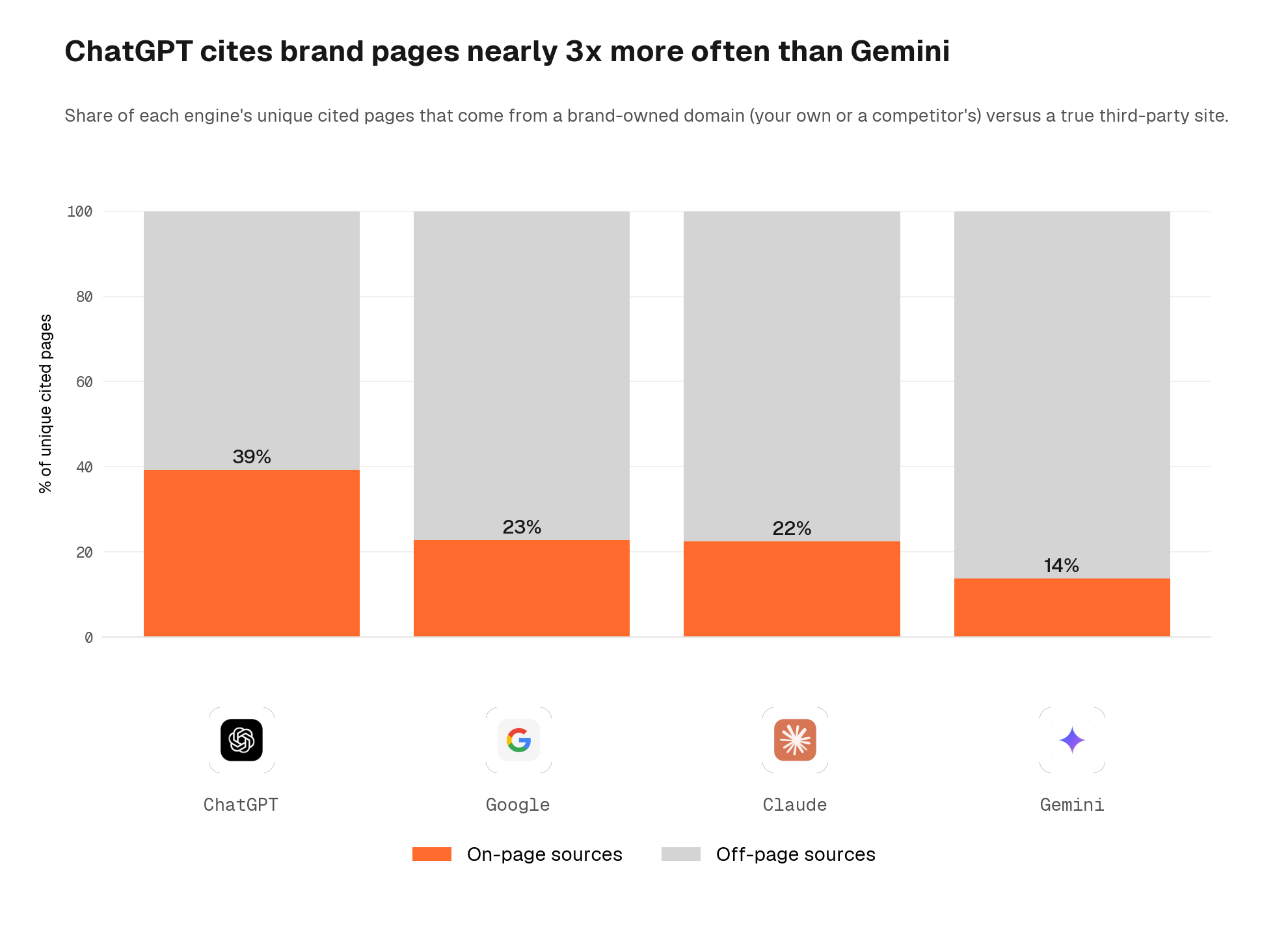
Page format and engine interaction
The largest format-engine effect is on pricing pages, where median citation age varies sharply across engines. Some engines pull pricing content within months; others treat it as static reference and cite versions years old. Comparison content cites freshly across engines, with median ages of 3 to 6 months everywhere. Articles and blog posts cluster around 6 to 10 months across engines.
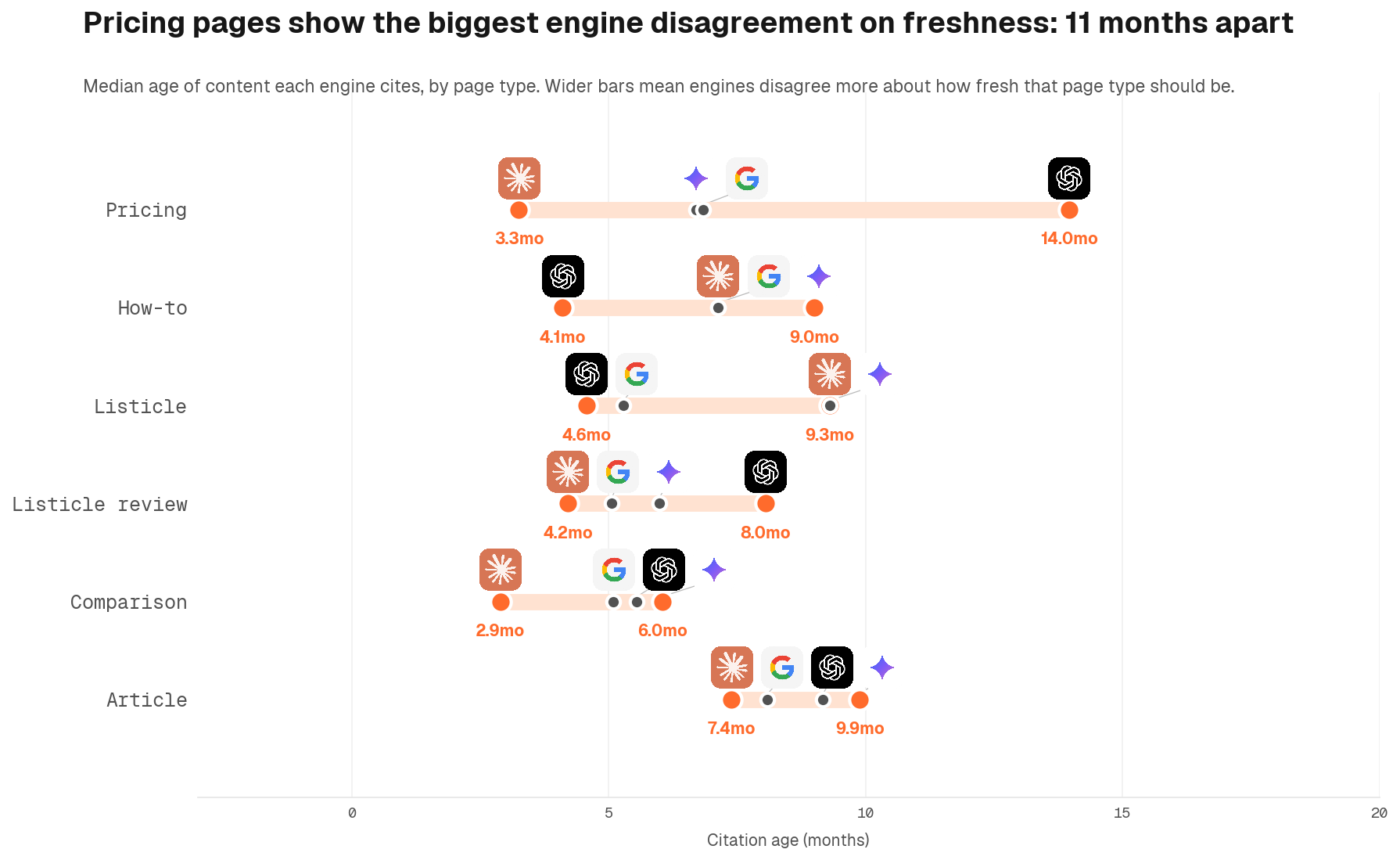
The practical implication is to calibrate to the most demanding engine in the set, not the most permissive one. Engine preferences shift as models improve and user behaviour changes: what ChatGPT tolerates today may tighten next quarter. A refresh cadence that satisfies Claude's freshness threshold will remain competitive across all engines regardless of how the landscape shifts.
Page format hierarchy
Within a controlled multivariate model that includes domain fixed effects, content depth, alignment, and page age, page type still has substantial residual explanatory power. Pricing pages show a large positive coefficient (+0.39), and listicle reviews show a negative coefficient (-0.12). Comparison and how-to formats sit near the reference category.
The effect persists even after controlling for the alignment metric, which suggests page format is independently informative rather than merely a proxy for "this page happens to be aligned with commercial prompts."
The likely mechanism is that pricing and comparison pages tend to contain specific, dense, commerce-relevant content that AI engines treat as authoritative for transactional and evaluation prompts respectively. A comparison page that names competitors and compares features directly is structurally what an evaluation prompt is asking for. A pricing page is structurally what a transactional prompt is asking for. Format matches intent.
Pricing pages and comparison content punch above their weight on AI citations, even for top-of-funnel queries. Do not treat them as "BOFU only." Invest in deeply specific pricing details, comparison tables that name competitors, and feature breakdowns. These earn citations across the entire funnel.
AI-perceived domain authority dominates
In the XGBoost and SHAP analysis, AI-perceived domain authority (how much trust AI engines have accumulated for a domain based on its citation history, not a traditional link-based score) emerges as one of the two most important features alongside prompt-content alignment. It had a mean absolute SHAP value of 0.38, compared to the strongest non-alignment page-level feature at 0.06. In effect-size terms, AI-perceived domain authority is roughly 6 times as influential as the strongest individual page-level feature beyond alignment.
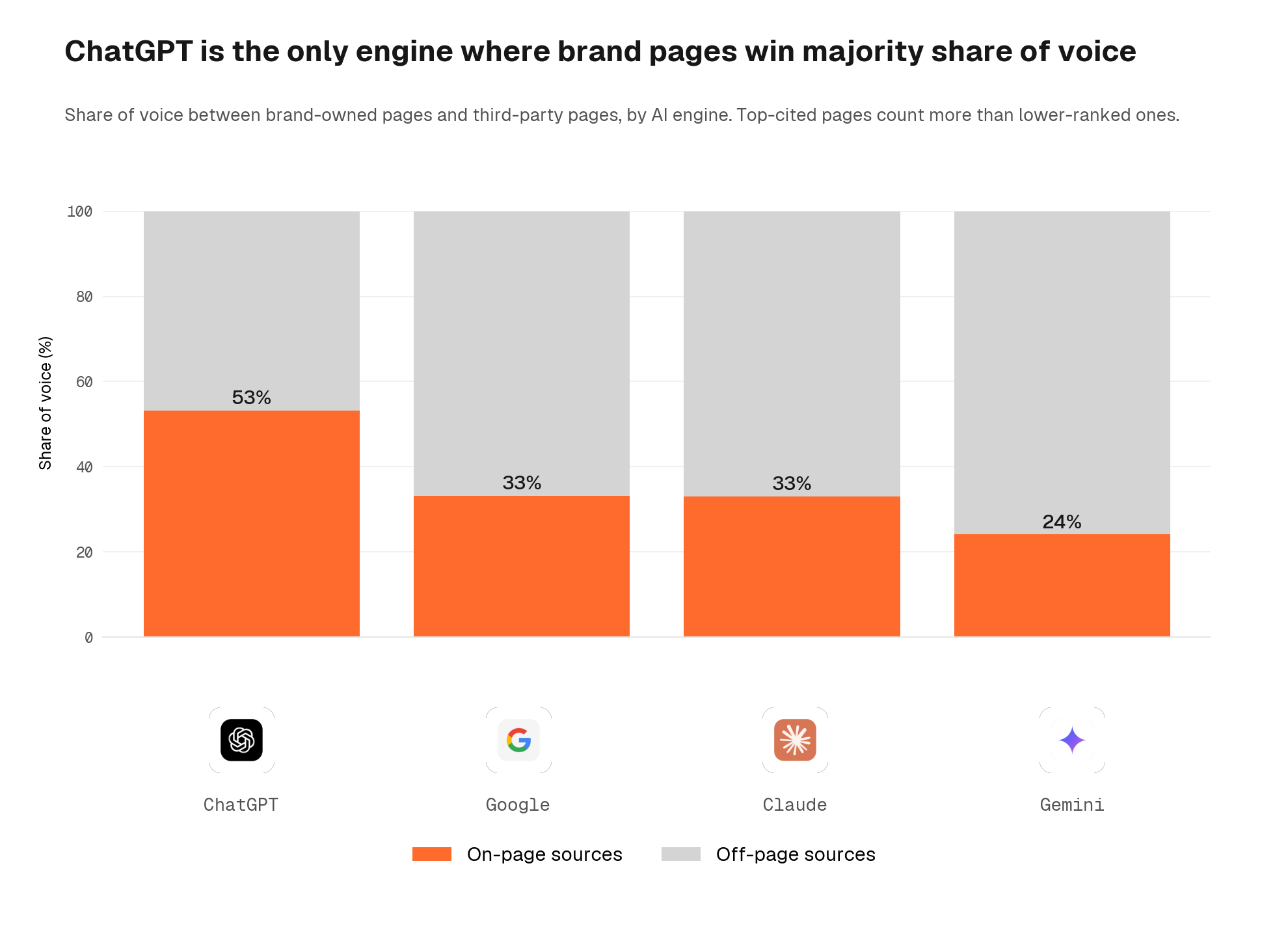
Brand versus third-party split sharpens with position-weighting
When we weight citations by their position in the AI response (top-cited URLs count more), the brand versus third-party split becomes even sharper. ChatGPT delivers 53% of its position-weighted share of voice to brand-controlled pages. Every other engine gives the majority of its weight to third-party sources. For brands, this means ChatGPT is the engine where on-page work earns the biggest return; for the other three, off-page authority and third-party visibility matter more.
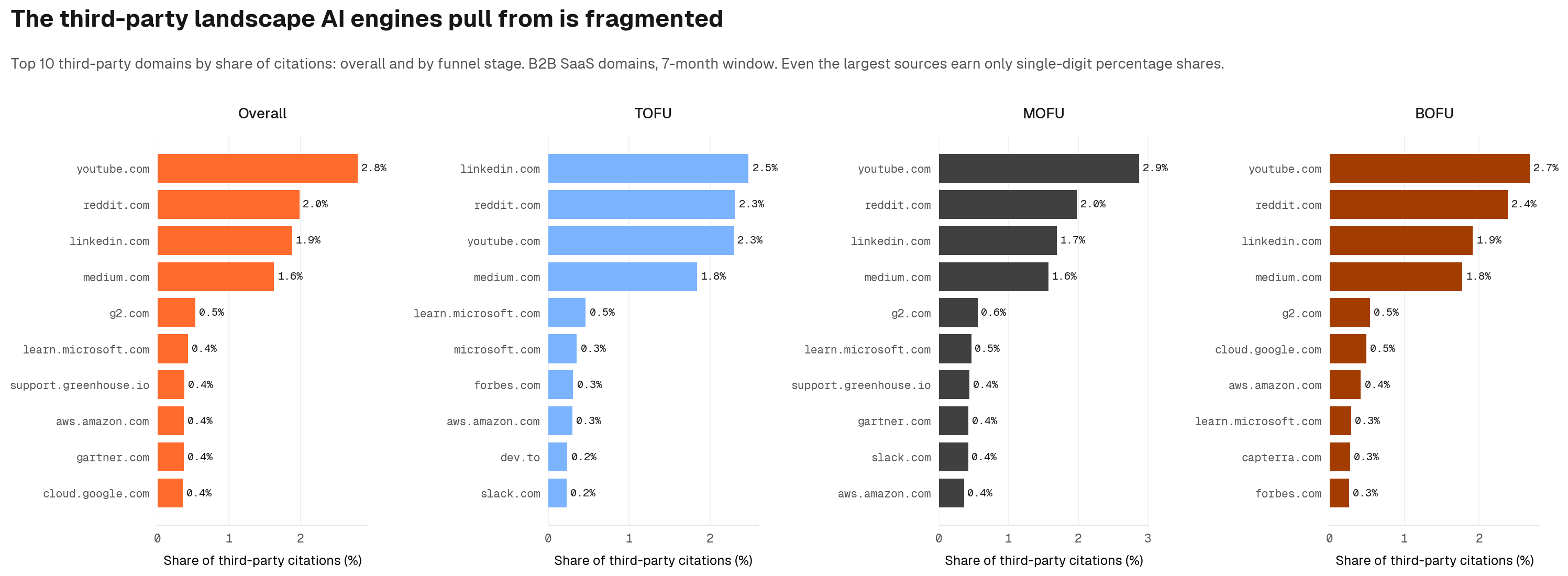
Which third-party platforms earn AI citations?
For the off-page side of the equation, the answer is dominated by a long tail of niche specialist sites. Even the best-known platforms, taken together, account for only a few percent of total third-party citations.
Within the named neutral platforms category specifically, LinkedIn ranks below Medium, Reddit, and YouTube once we deduplicate at URL level. Each platform earns its share through a different content type: LinkedIn through professional commentary, Reddit through community discussion, YouTube through how-to and review content, Medium through long-form articles.
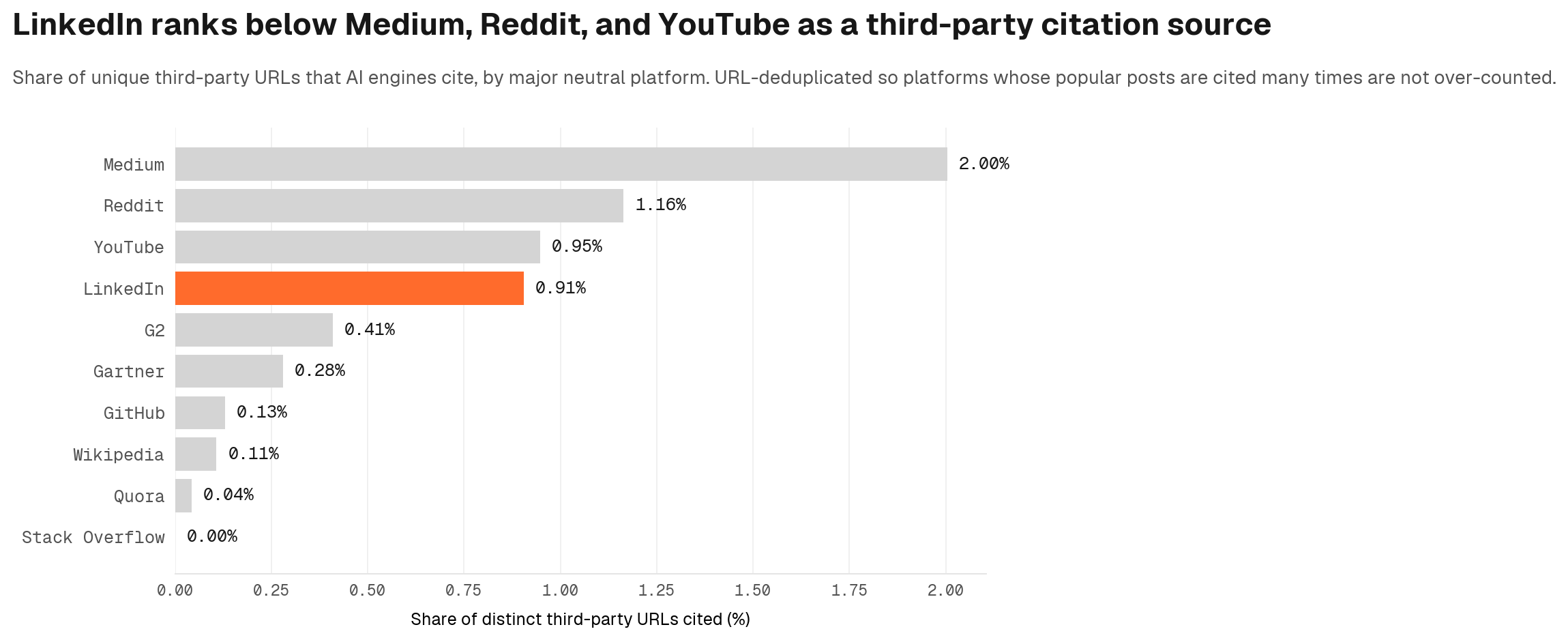
LinkedIn is a secondary priority, not a universal one
LinkedIn earns citations primarily through one surface: Google AI. 97% of the LinkedIn citations in our window came from Google AI alone. Claude and ChatGPT each cited LinkedIn in under 0.4% of their third-party citations. Gemini cited LinkedIn zero times. This means LinkedIn is a relevant secondary priority, specifically for brands whose buyers use Google AI Overviews or Google Search - it operates as an extended Google surface more than a general AI citation channel. Brands whose buyers lean on ChatGPT or Claude to evaluate vendors will see little citation lift from LinkedIn content alone. The primary off-page investment case for cross-engine coverage sits with YouTube and Reddit, which appear consistently across all engines at every funnel stage.
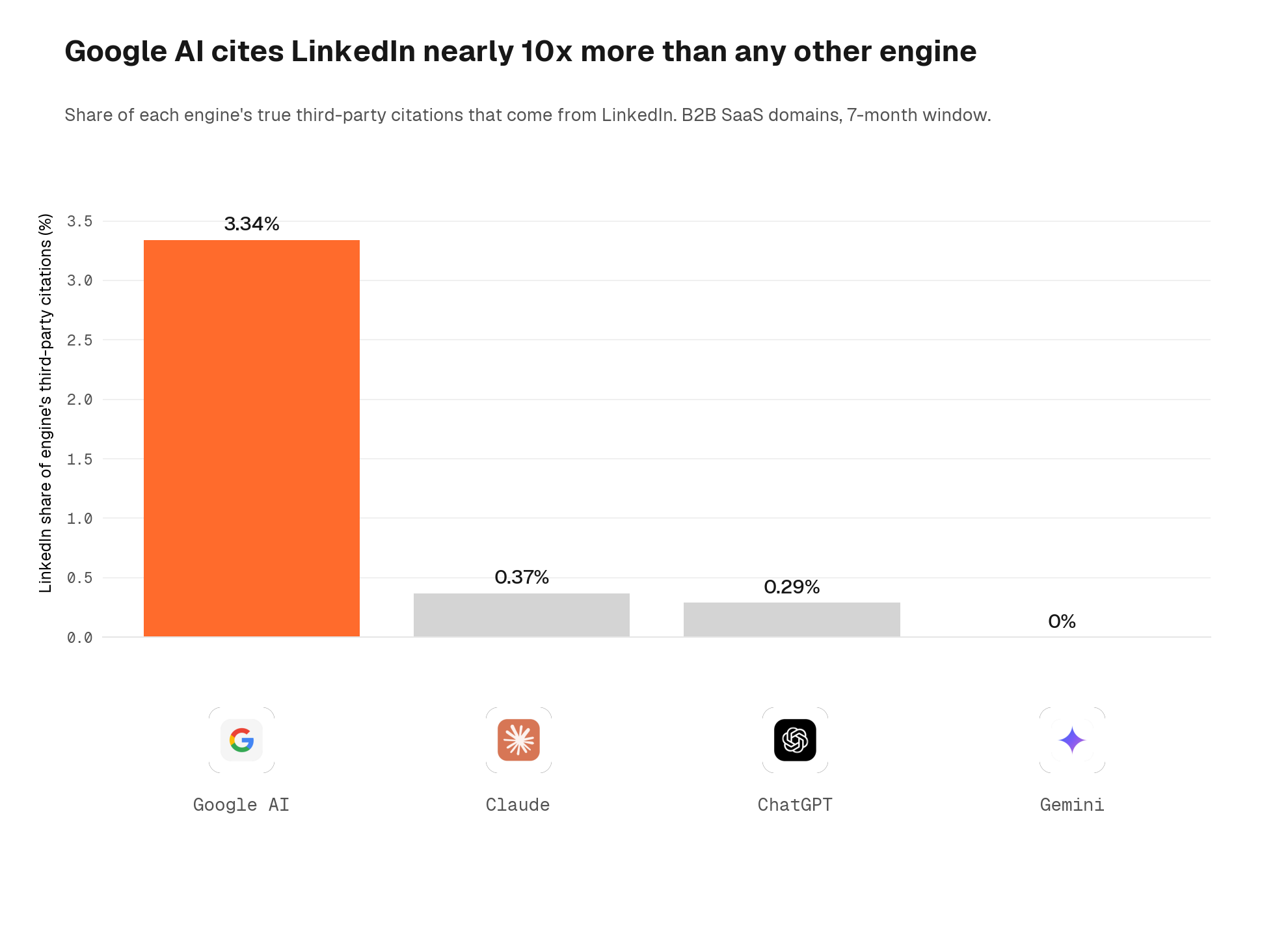
The implication for challenger brands is direct. No combination of on-page tactics can substitute for low brand authority. Off-page work, including backlinks, brand mentions, third-party citations, and earned media, is upstream of every page-level lever in this study. Page-level optimisation is necessary but not sufficient. Match your off-page channel to where your buyers search: LinkedIn lifts you on Google AI; Reddit and YouTube are universal across engines. For why Reddit specifically punches above its weight, see why Reddit is the primary signal for AI visibility.
The strategic priority stack
Based on the multivariate analysis, here is the priority stack for marketers investing in AI visibility. The list is sequenced. Each item depends on the items above it being already in place. For a 4-month implementation roadmap that operationalises this stack, see the Citable framework.
1. Build customer understanding first
Alignment to prompts is impossible without knowing how your buyers actually phrase their problems. Harvest first-party intelligence from sales calls, support transcripts, Reddit threads, customer interviews, and discovery sessions. Document buyer language verbatim before you write a line of content.
2. Match content to prompts
This is the highest-ROI on-page lever in the study. Use buyer language explicitly. Mirror question phrasing in headings. Place direct answers in the first 2 to 3 paragraphs. Test against the prompts your buyers are likely to send to AI engines.
3. Layer AEO best practices on top
Schema markup, FAQ sections, TLDR/BLUF blocks, fast page load, all help. They are multipliers on a strong content base. Do not skip them, but do not treat them as your primary lever either. The compounding effect on top of strong alignment is real.
4. Refresh content on an engine-aware cadence
Calibrate to the most demanding engine, not the most permissive one. Engine preferences shift as models improve and user behaviour evolves: a cadence that satisfies Claude's freshness threshold keeps you competitive across all engines regardless of how the landscape changes.
5. Build domain share of voice
Off-page authority is the structural foundation. Backlinks, earned media, brand mentions, and third-party citations compound every other lever in this analysis. For challenger brands, this is the bottleneck.
Priority summary
Each lever with its relative priority for marketers:
| Lever | Priority | Action timeline |
|---|---|---|
| Prompt-content alignment | High | Ongoing, every piece of content |
| Page format choice (pricing or comparison) | High | Strategic, content portfolio decisions |
| AI-perceived domain authority | High | Long-term, quarters and years |
| Page length and depth | Medium | Medium-term, where appropriate |
| Title-prompt similarity | Medium | Tactical, every piece of content |
| Engine-aware refresh cadence | Medium | Quarterly to annual |
| FAQ, TLDR, schema, speed | Important | Apply consistently: compounds every signal above it |
The further down this list you are, the more important it is that the items above are already in place. A pricing page with the wrong language is not a pricing page that earns citations. A perfectly schema-marked page on a low-authority domain will not displace the incumbent. The order is the playbook.
Next steps
If you want a personalised analysis of how your brand maps onto these findings:
- Free tool: AEO content evaluator to test your existing content against AI engine alignment
- Expert consultation: Book an AI Visibility Audit
- Comprehensive strategy: Explore our AEO services
The findings in this report are durable across engines and stable across robustness checks. The single highest-leverage action a marketer can take this quarter is auditing whether their highest-priority pages mirror the language buyers actually use when prompting AI engines. Everything else compounds against that foundation.
More research
If you found this report useful, our other long-form research goes deeper on adjacent topics:
- Why 99% of Reddit's influence on ChatGPT answers is invisible. An analysis of 144,000+ AI citations showing Reddit drives 27% of ChatGPT's search results but appears in less than 1% of visible citations.