14 Best SaaS SEO Agencies for B2B SaaS companies (2026 review)
Best SaaS SEO agencies for 2026, compared on pipeline reporting, pricing, and contract terms so a B2B SaaS marketing leader can shortlist a partner before the next discovery call.
Growth marketer and B2B demand specialist with expertise in AI search optimisation - I've worked with 50+ firms, scaled some to 8-figure ARR, and managed $400k+/mo budgets.
July 14, 2026
Published: May 29, 2026|Updated: July 14, 2026
23 mins
Last updated 14th July 2026
TL;DR
Pipeline first: The best SaaS SEO agencies report on MQLs (Marketing Qualified Leads), demos booked, and pipeline contribution, not just keyword positions or impressions.
Top pick: Discovered Labs leads this review with verified organic pipeline results across Sova Assessment (+167% organic demo requests), incident.io (+22% organic meetings booked), and Gladia (7x sales-accepted leads in 4 months), running SEO and AI search as one connected operation.
Contracts: Month-to-month terms reduce risk when search is shifting. Avoid 12-month lock-ins until you have proof of fit.
Two surfaces: Ahrefs data from early 2026 shows only 38% of AI Overview citations come from top-10 Google results, so ranking well and being cited in AI answers are two different problems that require different tactics.
The best SaaS SEO agencies in 2026 are Discovered Labs, Omniscient Digital, Skale, Directive Consulting, Grow and Convert, MADX Digital, Quoleady, Singularity Digital, Omnius, Generate More, First Page Sage, RevenueZen, Embarque, and NoGood.
Each is a specialist SaaS SEO agency that measures success in pipeline metrics, meaning trials, demos, and MRR, rather than vanity traffic. They differ in pricing transparency, contract terms, and how far they cover AI-generated answers alongside traditional Google rankings. Discovered Labs tops the list with verified SEO and AEO case studies for Sova Assessment, incident.io, and Gladia, published pricing, and month-to-month terms.
What to look for in a SaaS SEO agency
Six criteria separate agencies that drive pipeline from agencies that drive traffic charts. Each is covered in depth in the evaluation guide after the reviews.
Pipeline measurement: They report MQLs, demos booked, and pipeline contribution, not keyword positions or impressions.
SaaS sales-cycle fluency: They understand free trials, demo funnels, and 30 to 90 day B2B buying cycles.
A real content process: They can show you a sample brief and explain how QA holds at 20 or more pieces per month.
Their own site ranks: An agency that cannot prove ROI on its own website will struggle to prove it on yours.
Specific case-study metrics: Look for figures like cost-per-signup or demo growth, not screenshots of traffic curves.
A plan for AI search: One criterion among six, but a growing one. Ask how they measure citations in AI answers alongside rankings.
SaaS SEO agency comparison: pricing, contracts, and AI search capability
The table below gives you a fast read on each agency before the detailed reviews. Pricing reflects publicly available figures. Where an agency does not publish rates, the pricing model is described qualitatively.
Agency
Core focus
Pricing model
Contract terms
AI search capability
Discovered Labs
SEO + AI search (Answer Engine Optimization), one operation
Public tiers from €7,995/mo (~$8,600 USD)
Month-to-month
Yes, engineer-led, proprietary methodology
Omniscient Digital
B2B SaaS content and editorial SEO
Custom, from ~$10,000/mo
Typically 6-12 months
Yes, recently added
Skale
SaaS organic growth, SQL and MRR focused
Custom, reported from ~$8,000/mo
Retainer, embedded model
Yes, recently added
Directive Consulting
Multi-channel B2B (SEO, paid, CRO)
Custom, enterprise, not disclosed
Custom, multi-channel
Yes, DiscoverabilityOS for AI search
Grow and Convert
Bottom-funnel content SEO and GEO
Custom monthly retainer
Ongoing retainer
Yes
MADX Digital
Technical SEO and GEO, SaaS only
Reported from ~$2,749/mo
Monthly retainer
Yes, GEO across ChatGPT and Perplexity
Quoleady
Content-led SEO and link building
From €1,753/mo (~$1,900 USD)
Flexible, deliverable-based
Yes
Singularity Digital
Revenue-focused SEO, $1M-$10M ARR (Annual Recurring Revenue)
From $3,000/mo
Custom
Not specified
Omnius
SaaS and fintech, technical SEO + AEO
Custom, not publicly disclosed
Custom
Yes, with custom measurement
Generate More
AI-assisted content at scale
Published pricing, contact for details
Flexible
Yes
First Page Sage
Thought-leadership SEO at scale
Custom, typically $10,000-$20,000/mo
12-24 months
Yes
RevenueZen
Brand-led SEO and pipeline growth
Published packages, $3,000-$15,000/mo
Month-to-month
Yes
Embarque
Product-led content, on-demand SEO
Tiered monthly, from ~$1,800/mo
No long-term contract
Yes
NoGood
Growth marketing with SEO and content
Custom, not publicly disclosed
Custom
Yes
The SaaS SEO agencies on this list fall into three groups: Content-led agencies (Omniscient Digital, First Page Sage, Embarque, Quoleady, Grow and Convert) lead with editorial quality and bottom-funnel content, Pipeline-led agencies (Skale, Directive Consulting, Singularity Digital, RevenueZen) start from revenue goals and work backward to content. Systems-led agencies (Discovered Labs, Omnius, MADX Digital) treat technical SEO, content, and off-page signals as one operation measured across both traditional rankings and AI-generated answers.
1. Discovered Labs: SEO and AI search as one operation
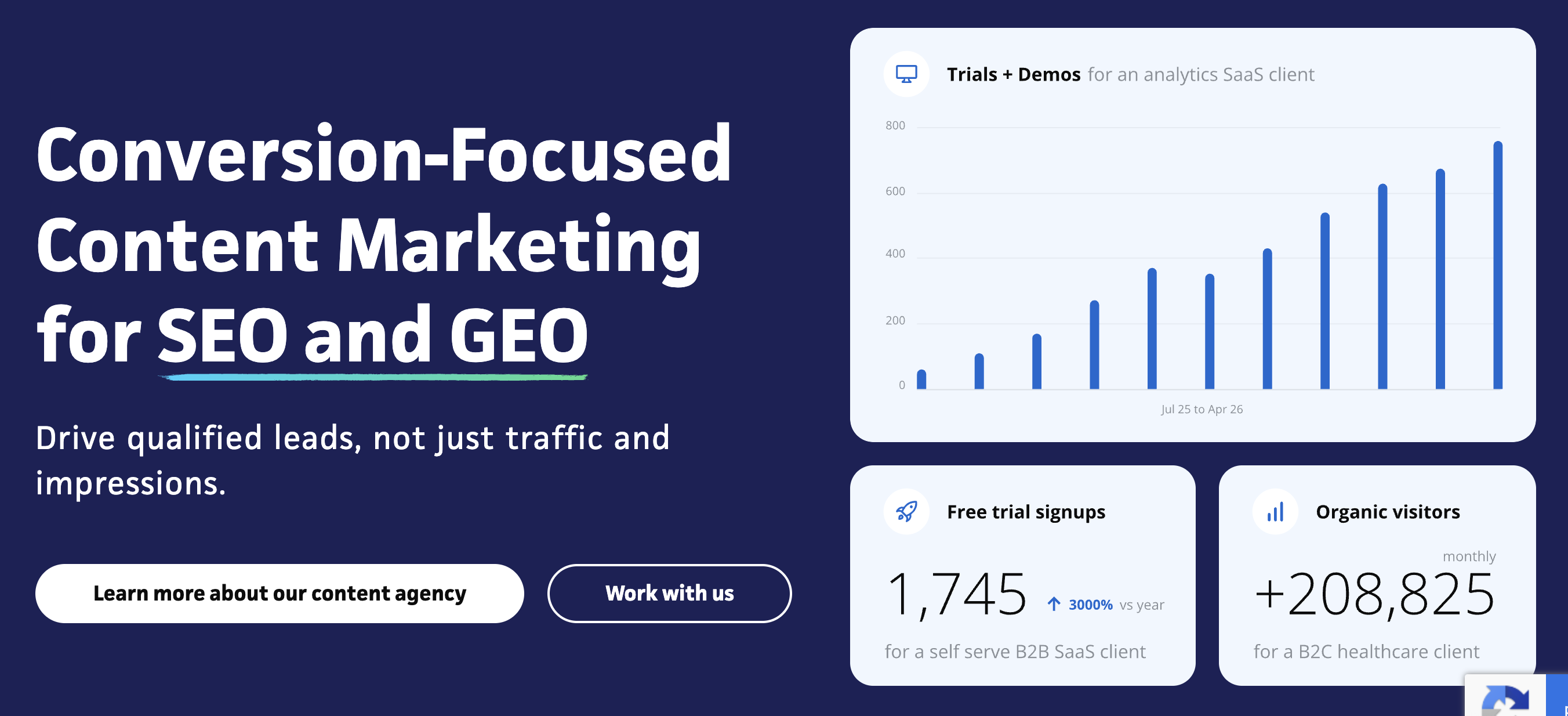
Discovered Labs is a B2B SaaS SEO agency that reports verified pipeline results, including +167% organic demo requests for Sova Assessment and 7x sales-accepted leads in 4 months for Gladia, and runs traditional SEO and AI search as one connected operation. It ranks first in this review because it proves results at the MQL and demo level, publishes pricing, and works month-to-month.
Approach to SaaS SEO
At Discovered Labs, we treat organic search as one channel running on two surfaces. Traditional SEO covering technical audits, on-page optimization, link building, and content operations runs alongside AEO services using our CITABLE framework, a 7-component system that structures content for passage retrieval in LLMs. The two surfaces share a single content pipeline, so we do not duplicate budget across two retainers. Our research into 144,284 AI citations found Reddit occupying roughly 27% of ChatGPT's search slots during query processing, which informs our off-page consistency strategy alongside traditional link building.
Results and case studies
Sova Assessment, a B2B assessment and testing platform, saw a +167% increase in organic demo requests, with organic search becoming the number one channel for leads and MQLs. incident.io, an incident management platform for engineering teams, booked 22% more organic meetings after we restructured their content for intent architecture and lifted their AI visibility from 38% to 64% on priority buyer queries. Tom Wentworth, CMO at incident.io, said:
"Before Discovered Labs, we were using homegrown LLM prompts, without a clear strategy for what to optimize for or exactly how best to structure content." - Verified user review of Discovered Labs
Gladia, an AI transcription and audio intelligence platform, grew sales-accepted leads 7x in 4 months, with 93% of AI-referred leads arriving from LLM search.
Pricing and retainers
All tiers are listed publicly at discoveredlabs.com/pricing. Establish is €7,995/mo (€6,995 at the 6-month rate) and covers up to 20 content units per month, AI visibility tracking, technical SEO, and Reddit mentions. Compete is €12,995/mo (€10,995 at the 6-month rate), adding net-new landing pages and a senior-led pod. Outlier starts from €15,995/mo and adds programmatic scale and a dedicated engineer.
Contract terms and engagement model
Every tier runs month-to-month. Longer commitments of 3 or 6 months come with a lower monthly rate. Flexibility is the accountability model: we stay because results compound, not because a contract requires it.
Best for
Series A+ B2B SaaS, $2M to $50M ARR, with a marketing leader who owns organic pipeline and needs to measure results across both Google and AI search without two separate retainers.
2. Omniscient Digital: editorial SEO for B2B SaaS
Omniscient Digital is an Austin-based organic growth agency for B2B software companies, with published case studies for Jasper and Loom. Their reputation rests on editorial quality and long-form content strategy.
Approach to SaaS SEO
Omniscient centers their SEO strategy on a barbell content approach: product-led content that converts, paired with broader editorial pieces that build topical authority. They map search intent across the full funnel and build comprehensive content calendars designed to rank for non-branded commercial terms. They are adding GEO and AEO capabilities as the market shifts.
Results and case studies
Omniscient publishes case studies for Jasper and Loom showing organic traffic growth and pipeline contribution. MQL and demo numbers are available directly from their case study library.
Pricing and retainers
Omniscient charges from $10,000 per month for full-service SEO. They quote custom scopes after a discovery process.
Contract terms and engagement model
Engagements typically run 6 to 12 months. Shorter strategy-layer pilots may be available before a full content retainer begins.
Best for
Mid-market to enterprise SaaS with an established content team that needs high-caliber editorial strategy and a partner comfortable at the top end of the market.
3. Skale: AI-search-first SaaS growth
Skale is a London-based organic growth agency for tech and SaaS brands, focused on SQLs, pipeline, and MRR over traffic and rankings. Founded in 2020, it positions itself as an AI-search-first partner that operates like an embedded SEO function inside the client's growth team.
Approach to SaaS SEO
Skale builds organic growth engines that treat SEO as an MRR channel, prioritizing commercial and bottom-funnel content plus technical SEO across both AI-driven search and Google. Their model embeds strategists into the client's team rather than working at arm's length.
Results and case studies
Skale reports outcomes in SQLs, pipeline, and recurring revenue rather than traffic volume. Client results are shared in selected public case studies and during the sales process.
Pricing and retainers
Skale does not publish standard rates. Reported retainers start around $8,000 per month, positioning them in the mid-to-upper tier of specialist agencies.
Contract terms and engagement model
Engagements run as ongoing retainers using an embedded-team model, with specifics set during onboarding.
Best for
Series A and B SaaS companies that want an embedded SEO function focused on MRR and are already investing in AI-driven search.
Directive Consulting is a B2B marketing agency, founded in 2014 by Garrett Mehrguth, that reports 420 or more brands served and over $1B in revenue generated. Its Customer Generation methodology unifies SEO, paid media, and conversion rate optimization under one revenue goal.
Approach to SaaS SEO
Directive runs SEO as one channel inside its Customer Generation model, holding every capability accountable to pipeline and revenue rather than MQLs. SEO, paid, and CRO are planned together for enterprise SaaS with complex sales cycles, and their DiscoverabilityOS extends the model to AI search.
Results and case studies
Directive publishes case studies across enterprise B2B and SaaS, reporting pipeline and revenue impact, and cites 420 or more brands served and over $1B in revenue generated.
Pricing and retainers
Directive does not publish standard pricing. Engagements are custom and positioned at the enterprise end of the market.
Contract terms and engagement model
Engagements are scoped to the channel mix and typically run as longer-term, multi-channel programs.
Best for
Enterprise SaaS with complex sales cycles that want SEO inside a multi-channel program measured on qualified pipeline, not leads.
5. Grow and Convert: bottom-funnel content that converts
Grow and Convert is a content-focused SEO and GEO agency known for its pain-point SEO methodology, which prioritizes bottom-funnel content that converts readers into signups over high-traffic awareness content.
Approach to SaaS SEO
Grow and Convert builds content around the specific problems buyers search at the point of purchase, then measures each article by the leads and signups it produces. Their GEO work extends the same bottom-funnel logic to AI-generated answers.
Results and case studies
Grow and Convert publishes case studies tying content to leads and conversions across B2B, self-serve SaaS, and demo-based SaaS clients, with an emphasis on conversion rather than traffic volume.
Pricing and retainers
Grow and Convert works on a custom monthly retainer, quoted by scope rather than published as fixed tiers.
Contract terms and engagement model
Engagements run as ongoing content retainers, with scope set by publishing cadence and target funnel stage.
Best for
Mid-market B2B and SaaS teams that want bottom-funnel content engineered to convert into signups, not top-of-funnel traffic.
6. MADX Digital: GEO and technical SEO for SaaS
MADX Digital is a search agency that works exclusively with SaaS companies, combining content, digital PR, link building, and GEO into one growth system built to generate qualified inbound pipeline through Google, ChatGPT, Perplexity, and other engines.
Approach to SaaS SEO
MADX integrates technical SEO, content, digital PR, and GEO into a single revenue-first system, with always-on dashboards tied to pipeline rather than vanity metrics. They optimize for AI answer engines alongside traditional rankings.
Results and case studies
MADX publishes SaaS case studies, including work with MoonPay and UPSTIX, focused on qualified inbound pipeline.
Pricing and retainers
MADX publishes reported pricing starting around $2,749 per month, placing them at the accessible end of the specialist market.
Contract terms and engagement model
Engagements are structured as monthly retainers with live, revenue-tied reporting.
Best for
B2B SaaS companies that want technical SEO and GEO integrated into one revenue-first system with transparent, pipeline-tied reporting.
7. Quoleady: content-led SEO for SaaS
Quoleady is a European SaaS content and SEO agency that has worked with Monday.com and Expandi. They are known for high-intent content production and SaaS-specific link building.
Approach to SaaS SEO
Quoleady builds content strategies around high-intent buyer queries, prioritizing commercial and BOFU terms over brand-awareness traffic. Their GEO approach emphasizes comprehensive guides structured around buyer questions, alongside link acquisition campaigns targeting SaaS and tech publications.
Results and case studies
Their public case studies show organic traffic growth and demo sign-up improvements for clients in competitive SaaS categories. Pipeline numbers depend on client attribution setup and are available on request.
Pricing and retainers
Quoleady structures engagements by word count rather than article count. Their Starter package begins at €1,753 per month (approximately $1,900 USD) for 7,500 words, while their Pro package is €5,012 per month for 20,000 words. Average client budgets are around $4,000 per month.
Contract terms and engagement model
They operate a flexible, deliverable-based billing model with no rigid long-term lock-in, which suits early-stage teams that need to adjust scope quickly.
Best for
Early to mid-stage B2B SaaS companies that need to scale content production and build topical authority quickly, particularly in competitive European markets.
8. Singularity Digital: revenue-focused SaaS SEO
Singularity Digital is a revenue-first SEO agency for SaaS companies between $1M and $10M ARR, positioned as a hands-on partner rather than a content-volume shop.
Approach to SaaS SEO
Their SaaS SEO approach centers on a custom Keyword Opportunity Blueprint that combines Ahrefs data with lead volume, conversion rates, and customer LTV to identify the most valuable keywords to target. This gives commercial teams a clear cost-and-revenue view of ranking opportunities before content investment begins.
Results and case studies
Singularity focuses on demo request and pipeline growth for early-stage SaaS clients. Specific case study metrics are shared during the sales process rather than published publicly.
Pricing and retainers
Retainers start at $3,000 per month, making them accessible for seed-stage teams with a defined SEO scope.
Contract terms and engagement model
They discuss contract terms during onboarding on a custom basis. Their lower price tier typically corresponds to a more defined scope rather than a full-service engagement.
Best for
Bootstrapped or Series A SaaS companies needing a direct, revenue-first SEO partner that ties keyword selection explicitly to pipeline value.
9. Omnius: technical SEO and AEO
Omnius is a technical SEO agency for SaaS and fintech companies that combines traditional SEO, AEO, and GEO in one engagement, and they have built proprietary AEO attribution tooling.
Approach to SaaS SEO
Omnius runs a reversed-funnel approach, prioritizing BOFU and commercial pages before investing in TOFU awareness content. They define 12-month KPIs and precise workflow protocols at the start of each engagement, and their AEO layer optimizes for Google AI Overviews and AI assistant citations alongside traditional rankings.
Results and case studies
Omnius publishes results focused on qualified leads and MQL volume in competitive fintech and SaaS verticals. Case study specifics are available to prospective clients on request.
Pricing and retainers
Omnius does not publish pricing. They scope engagements based on project complexity, competitive environment, and growth objectives.
Contract terms and engagement model
Engagements are structured around 12-month KPI definitions, which suggests a commitment aligned with those timelines.
Best for
Complex SaaS and fintech products requiring deep technical SEO combined with clear attribution and AI search coverage from the outset.
10. Generate More: AI-assisted content at scale
Generate More is a Finland-based SEO and content agency that leads with AI-assisted content production and publishes transparent pricing, which remains unusual in the agency market.
Approach to SaaS SEO
Generate More builds content programs designed for high-volume publication, using AI tooling to accelerate production while maintaining editorial oversight. Their focus is on building topical authority through content depth and consistent publishing frequency.
Results and case studies
Their published case studies show organic traffic and lead growth for clients that need to build authority in new topic areas quickly. Pipeline metrics are included for clients with CRM attribution in place.
Pricing and retainers
Generate More publishes pricing on their website. Contact them directly for current tier details and content volume options.
Contract terms and engagement model
Engagements are structured flexibly, with clear deliverable lists per tier and the ability to adjust scope as content programs scale.
Best for
High-growth startups that need to build topical authority rapidly through consistent content publishing and want cost predictability from day one.
11. First Page Sage: thought-leadership SEO at scale
First Page Sage is a San Francisco SEO agency offering fully outsourced, thought-leadership-driven SEO for mid-market and enterprise SaaS, with a methodology built around publishing frequency and domain authority.
Approach to SaaS SEO
First Page Sage combines SEO with GEO and thought leadership to create organic lead generation programs. They build a strategic keyword plan at the start of each engagement and publish high-quality content on a regular cadence, with the goal of capturing both traditional rankings and AI-generated answer placements.
Results and case studies
First Page Sage has an extensive case study library showing long-term organic traffic growth across SaaS and professional services verticals. Case studies emphasize traffic volume and conversion improvements.
Pricing and retainers
They quote retainers on a custom basis, typically $10,000 to $20,000 per month.
Contract terms and engagement model
Standard contracts run 12 to 24 months to allow the compounding content model to produce measurable results.
Best for
Well-funded mid-market and enterprise SaaS companies that want a fully outsourced content engine with high editorial standards and a long-term compounding strategy.
12. RevenueZen: brand-led SEO and pipeline growth
RevenueZen is a B2B SaaS SEO agency focused on organic brand building and pipeline growth, and one of the few on this list publishing both pricing and month-to-month terms.
Approach to SaaS SEO
RevenueZen starts every engagement with analytics setup and proactive pipeline goal-setting. Their content strategy is built from documented customer needs and validated buyer intent data, with GEO tactics layered in to capture AI-generated answer placement alongside traditional rankings.
Results and case studies
Their case studies focus on pipeline and revenue growth rather than traffic volume, with results reported at the MQL and opportunity level for clients using HubSpot or Salesforce attribution.
Pricing and retainers
RevenueZen publishes six packages on their pricing page, running from $3,000 to $15,000 per month depending on scope.
Contract terms and engagement model
RevenueZen offers month-to-month retainers with no long-term contract requirements, which lowers the switching cost for teams moving from an underperforming agency.
Best for
B2B SaaS companies with a clear brand identity that need to capture high-intent organic demand and want pipeline-level reporting without a long-term lock-in.
13. Embarque: product-led content and on-demand SEO
Embarque is an on-demand SEO and content agency for product-led SaaS, operating without long-term contracts and with transparent tiered pricing from around $1,800 per month.
Approach to SaaS SEO
Embarque integrates the client's product naturally into content at the point of reader need, rather than as a pitch at the end of an article. This product-led approach is designed to improve conversion rates from organic traffic by showing the product solving the reader's problem in context.
Results and case studies
Embarque publishes case studies showing conversion rate improvements and lead growth for clients across SaaS verticals, with particular strength in product-led growth companies.
Pricing and retainers
Embarque publishes pricing transparently, starting from around $1,800 per month with tiers scaling by content and optimization scope.
Contract terms and engagement model
No long-term contract is required. Teams can scale up or pause based on production needs, which suits companies with variable content requirements across launch cycles.
Best for
Product-led growth SaaS companies that need high-quality content writing without long-term commitments, particularly those with strong product differentiation to build into organic content.
14. NoGood: growth marketing with SEO
NoGood is a full-stack growth agency with an active SEO and content practice, serving B2B SaaS companies that want organic search inside a broader growth program.
Approach to SaaS SEO
NoGood integrates SEO with paid and CRO to build programs that cover the full acquisition funnel. Their content work focuses on demand capture and conversion, with SEO positioned as one growth lever inside a connected program rather than a standalone channel.
Results and case studies
NoGood publishes results across their client base showing traffic growth and lead volume increases in competitive SaaS categories. Full pipeline metrics are shared during the sales process.
Pricing and retainers
NoGood does not publish pricing. They scope engagements based on the channels included.
Contract terms and engagement model
Contract terms are custom. Teams looking for SEO-only work may find the full-stack model broader than their immediate need.
Best for
SaaS companies that want organic search inside a connected growth program covering paid, organic, and conversion optimization under one partner.
How to choose a B2B SaaS SEO agency
Choosing an SEO agency for SaaS companies is a high-stakes decision. A wrong fit costs six months of budget and no pipeline to show for it.
Case studies with pipeline metrics
A credible SaaS SEO agency proves itself with case studies that report MQLs, demos booked, or pipeline contribution, not traffic or total keywords ranked. Traffic without attribution tells you nothing about whether the work drove revenue. If an agency's results page shows only traffic charts and keyword count growth, ask directly what the MQL outcome was before accepting the case study as proof.
Technical SEO depth for product-led sites
SaaS sites carry specific technical challenges: programmatic landing pages, app subdomains, JavaScript rendering, and indexation gaps that block Google from seeing pages you want ranked. Ask any agency to describe how they handle your site's indexation before you see a content proposal.
Scaling output without sacrificing quality
Content velocity is only a differentiator if editorial quality holds at volume. Ask to see a sample brief from a comparable client, and ask how QA gates work when the operation runs at 20 or more pieces per month.
Liam Collins, Head of Performance Marketing at Instantly, noted of Discovered Labs:
"We're working with Discovered Labs and have achieved excellent results. Highly recommend the team's delivery. They consistently put out a higher volume of content than the norm." - Verified user review of Discovered Labs
Connecting organic traffic to revenue
CRM attribution (HubSpot or Salesforce) and "how did you hear about us" survey data are the minimum for organic pipeline reporting. Ask any prospective agency how they map organic touches to closed deals, and what their standard month-one report looks like. If the answer is a traffic dashboard, that is a signal the agency is not ready to defend its work in a quarterly business review. Ahrefs data from early 2026 shows only 38% of AI Overview citations come from pages ranking in the top 10, so if you plan to measure AI visibility alongside organic, expect the attribution path to differ from traditional organic.
Matching the agency to your stage
Pre-PMF: Do not hire an agency yet. Founder-led content and 5 to 10 bottom-funnel pages cover what you need until positioning stabilizes.
Seed: A deliverable-based provider (Embarque, Quoleady) or a defined-scope partner (Singularity Digital from $3,000 per month, MADX Digital reported from around $2,749 per month) fits budgets under $5,000 per month.
Series A to D: A specialist retainer that reports at the pipeline level. This is the segment Discovered Labs is built for ($2M to $50M ARR), alongside Skale, RevenueZen, Grow and Convert, and Omniscient Digital.
Series C+ with enterprise budgets: Long-cycle compounding programs (First Page Sage, typically $10,000 to $20,000 per month) or full-stack and multi-channel partners (Directive Consulting, NoGood).
When you do not need a full agency
An honest read: a retainer is the wrong buy in three situations. If you are pre-product-market-fit, your positioning will change faster than content can compound. If you are under roughly $1M ARR, a SaaS SEO consultant or a deliverable-based provider gives you the strategy layer without the retainer overhead. And if your only blocker is technical, such as indexation gaps or site architecture, a one-off technical audit fixes it without a monthly commitment.
Questions to ask an SEO agency for SaaS companies
We use the CITABLE framework internally to structure content for both Google and LLM retrieval. It is equally useful as a vetting tool: ask any agency how they would apply each component to your highest-priority landing page.
Capturing non-branded search demand
Ranking for your brand name is baseline. The pipeline question is how much non-branded commercial traffic your program captures. Map your top 50 buyer queries and check which ones return your domain in positions 1 to 10, then treat those gaps as the primary brief for any SEO partner you hire. Our video starting SEO in 2026 walks through this audit practically.
Mapping intent to funnel stages
BOFU content (demo requests, free trial comparisons, pricing queries) drives pipeline directly. MOFU content feeds BOFU pages through internal links. TOFU content builds topical authority over time. A credible agency proposal shows you the distribution across these stages and explains which tier is most constrained in your current program.
Applying CITABLE to SaaS page design
The CITABLE framework has seven components covering entity clarity, intent architecture, third-party validation, answer grounding, block structure, consistency, and entity relationships. A page built to CITABLE performs for both Google passage indexing and LLM retrieval. Our free AEO content evaluator scores your pages against the framework at no cost.
Pipeline attribution for SEO
Attribution across organic search requires UTM tagging on all inbound links, first-touch and multi-touch attribution models in HubSpot or Salesforce, and "how did you hear about us" fields on demo and sign-up forms. AI-referred traffic adds a fourth input: source tags from LLM referrals, which analytics platforms are beginning to surface separately from direct traffic. Any agency you hire should describe the attribution path from first organic touch to closed deal before the retainer begins. Our AI visibility platform buyer's guide details how to choose the right measurement tooling for the AI surface, and our real citation rate benchmarks post explains why platform-reported numbers typically understate actual visibility.
If you want a baseline before committing to a partner, request a Search Visibility Diagnostic (€4,370 one-off, fully credited to your first retainer if signed within 14 days). You will see where your brand stands across both Google and AI search, with a competitive benchmark and a quick-wins list included.
FAQs about hiring a SaaS SEO agency
What does a SaaS SEO agency do?
A SaaS SEO agency grows a software company's organic pipeline through technical SEO, content production, and link building targeted at commercial buyer queries. The best agencies report results in MQLs, demos booked, and pipeline contribution rather than traffic volume, and increasingly optimize for AI-generated answers alongside traditional Google rankings.
What are the best SaaS SEO agencies in 2026?
The best SaaS SEO agencies in 2026 are Discovered Labs, Omniscient Digital, Skale, Directive Consulting, Grow and Convert, MADX Digital, Quoleady, Singularity Digital, Omnius, Generate More, First Page Sage, RevenueZen, Embarque, and NoGood. All specialize in organic growth for B2B SaaS, differing in methodology, pricing transparency, and whether they treat AI-generated answers as part of one organic search operation.
How much does a SaaS SEO agency cost?
Across the 14 SaaS SEO agencies compared in this guide, published and reported retainers run from about $1,800 to $20,000 per month. MADX Digital starts around $2,749, Embarque near $1,800, Quoleady near $1,900, Singularity Digital from $3,000, Skale reported from around $8,000, RevenueZen from $3,000 to $15,000, and First Page Sage $10,000 to $20,000. Discovered Labs publishes tiers from €7,995 per month, about $8,600.
Should you hire a SaaS SEO company or build an in-house team?
Hire a SaaS SEO company when you need senior strategy, content velocity, and AI-search coverage faster than you can recruit for it. An in-house hire suits companies with a stable, long-term content need and the budget for a full team. Many B2B SaaS companies start with an agency to build the engine, then bring maintenance in-house once the playbook is proven.
How do I choose the best SaaS SEO agency in the USA?
Prioritize B2B SaaS specialization and pipeline-level reporting over location when choosing a SaaS SEO agency in the USA. Omniscient Digital (Austin), First Page Sage (San Francisco), and Directive Consulting are US-based, and most specialist agencies work with US clients remotely. Discovered Labs publishes case studies reporting organic demo requests and organic meetings booked.
Should I trust Reddit threads recommending the best SaaS SEO agencies?
Treat Reddit as a shortlist builder, not a verdict. Threads asking for the best SaaS SEO agencies surface unfiltered client experiences, but recommendations are anecdotal and sometimes self-promotional. Names that keep appearing across shortlists and roundups include Skale, Directive Consulting, Grow and Convert, and MADX Digital.
Should an SEO agency for SaaS companies prove ROI on its own website?
Yes. A SaaS SEO agency should rank for its own commercial keywords and generate its own pipeline organically. Search the terms you would use to find a provider and note who appears, then ask shortlisted agencies where their own leads come from. An agency that cannot do SEO for itself is a weak signal for client work.
How long does it take for SaaS SEO to generate leads?
Most SaaS SEO programs take 3 to 6 months to produce a consistent flow of leads. Technical fixes such as indexation gaps and crawl errors can move rankings within weeks, while content programs compound over subsequent quarters. AI citation improvements can appear earlier for brands already ranking but not yet cited.
How do I verify a B2B SaaS SEO agency's case studies show real pipeline impact?
Ask whether results were measured at the MQL, demo, or pipeline level in the client's CRM, and which attribution model was used. Strong case studies name unit economics such as cost-per-signup or cost-per-demo rather than traffic screenshots. A B2B SaaS SEO agency that cannot tie its work to CRM records is reporting activity, not revenue.
What makes Discovered Labs different from other SaaS SEO agencies?
Discovered Labs is a B2B SaaS SEO agency that runs SEO and AI search as one operation, publishes its pricing, and works month-to-month. Verified results include +167% organic demo requests for Sova Assessment, +22% organic meetings booked for incident.io, and 7x sales-accepted leads in 4 months for Gladia.
How is AI search different from traditional SEO for pipeline attribution?
AI-referred visitors usually arrive as direct or referral traffic rather than tracked organic clicks, so measuring them requires separate setup from traditional SEO attribution. The optimization signals differ too. LLMs select passages based on structure and third-party consistency rather than backlink authority, so a modern SaaS SEO program measures both surfaces without merging the numbers.
Glossary: SaaS SEO and AI search terms
AEO (Answer Engine Optimization): The practice of optimizing content to be selected and cited by AI-powered search engines and large language models like ChatGPT, Claude, Perplexity, and Google's AI Overviews. Distinct from traditional SEO, which focuses on ranking in traditional search results.
GEO (Generative Engine Optimization): The practice of optimizing content specifically for generative AI systems that synthesize answers rather than return ranked lists. Often used interchangeably with AEO.
RAG (Retrieval-Augmented Generation): A technical architecture used by AI systems to retrieve relevant passages from external documents and use them to generate informed responses. The "block-structured for RAG" principle means content is formatted in discrete, self-contained sections that AI systems can easily extract and reference.
MQL (Marketing Qualified Lead): A prospect who has engaged with marketing content and meets defined criteria indicating sales readiness, such as downloading a resource, attending a webinar, or requesting a demo.
CAC (Customer Acquisition Cost): The total cost of acquiring a new customer, including all marketing and sales expenses divided by the number of new customers acquired in a given period.
ARR (Annual Recurring Revenue): The value of recurring revenue normalized to a one-year period, a key metric for subscription-based SaaS businesses.
TOFU (Top of Funnel): Content and marketing activities targeting prospects in the early awareness stage who are just discovering they have a problem.
MOFU (Middle of Funnel): Content targeting prospects who are evaluating solutions and comparing options.
Citation rate: The percentage of AI answers that link to your domain as a source, measured per target prompt across a defined set of buyer queries. Distinct from brand mention rate, which tracks how often your brand name appears in AI responses without a source link.
Share of voice: Your brand's citation or mention rate relative to competitors across a defined set of buyer queries in either Google search results or AI-generated answers.
Non-branded clicks: Organic search clicks from queries that do not include your company or product name. The core measure of how much category demand your SEO program captures.
Passage retrieval: The mechanism by which LLMs select specific sections of text from source documents to synthesize an answer, as distinct from returning a ranked list of pages. Covered in depth in research by Karpukhin et al. on dense passage retrieval.
CITABLE framework: Discovered Labs' 7-component content structure for LLM passage retrieval: Clear entity and structure, Intent architecture, Third-party validation, Answer grounding, Block-structured for RAG, Latest and consistent, Entity graph and schema.
AI Overview: Google's AI-generated answer block appearing above traditional organic results for certain queries, drawing citations from pages that may or may not rank in the top 10.
Pipeline contribution: The share of revenue-generating opportunities (MQLs, demos, closed deals) attributable to a specific marketing channel, here organic search.
BOFU content: Bottom-of-funnel content targeting buyers who are close to a decision: comparison pages, pricing pages, demo request landing pages, and use-case pages.
Most AEO dashboards report rate moves without uncertainty bounds. Here's the math and the prompt-set, variance, and trend tests every measurement should pass.
Google AI Overviews does not use top-ranking organic results. Our analysis reveals a completely separate retrieval system that extracts individual passages, scores them for relevance & decides whether to cite them.
Our team analyzed network traffic from Google AI Mode in January 2026. The capture included 547 Google flows and over 1,300 total requests during AI Mode sessions. The findings paint a clear picture of how Google is preparing to monetize AI-generated search results.